Two heads are better than one. How about more?
January 30, 2014 2 Comments
I like hiking a lot, especially with a few good friends of mine. But when the scenery is wild, or when the weather conditions are harsh, it is not uncommon to lose trail, or at least – be in doubt whether we are going the right way. In these situations we discuss with each other, consulting as well a map and compass. And even if none of us is certain about the right path we need to take on an overgrown crossroad, we usually manage to reach the mountain hut as we planned.
A common wisdom says that two heads are better than one. In this article we will investigate empirical basis for this claim. Additionally, we will look at frameworks quantifying performance in simple tasks, trying to answer how does ‘doing better’ scale with the number of participants, and their skills.
Perhaps the best known instance were a group of people can do better than a single expert is the so-called wisdom of crowds. This is a scenario, where we can collect a big number of guesses. They may be with high variance, but once averaged sometimes the collective guess happens to be very close to the actual value. The classical example is estimation of weight of an ox, described by Francis Galton in 1907. No one of 800 participants guessed the right weight, but their median guess was within 1% of the actual weight. (Of course, the answer is not always so close – except for the noise, one needs to know how to scale variables, e.g. they can be forming a logarithmic distribution; moreover, for every practical data there will be some bias, which (in some cases) may be the main factor.) Curiously enough, you can make and improvement by asking the same question to a single person a few times, and then averaging the answers [1].
However, averaging does not always work. One numerical quantity that you can average for a meaningful result is not available in every problem. Moreover, in some areas the difference of skill and knowledge may be high among participants. For example, you can imagine polling people on the masses of elementary particles (in this case, there will be not only huge variance of answers, but also – bias). Or to show that bias is not the only problem, you can try asking questions like “Which of two words in Swahili has a more positive connotation?”. Here bias is unlikely, but still it’s better to ask 1 native speaker than 100 people (out of whom 1 is a native speaker and most of 99 people are barely aware that Swahili is a language). Of course, in the limit of 
I want to concentrate on perceptual tasks, instead of guessing numerical values. Consider the Two-Alternatives Forced Choice (or 2AFC) paradigm with a pair of people collaborating to make the best binary decision. But before going further, a simple question…
Which one is bigger? (Perceptual tasks)

Your answer can depend on your screen resolution, your perception and other factors. But if you are not sure – try asking a few more people to see the same thing.
Bahrami et al. [2] gave participants two sets of Gabor patches. In one trial, one patch has a slightly different contrast that others. Participants were to choose which set had a different patch. Then they were allowed to communicate and make a joint decision. The contrast difference was an independent variable, with sign representing whether first or second set of Gabor patches had higher contrast. Rather than just counting the number of correct answers, the experimenters have plotted number of answers “B” as a function of 

In the above figure, a Gauss error function curve is fitted to the experimental data. The parameter quantifying responders’ (both individuals and pairs) skill was the maximal slope of that function, s. The shaded area is proportional to the error rate for uniform sampling. The key thing here is to find the dyad (i.e. pair) performance 
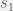
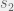
For example, if we consider the strategy that when they agree they give their mutual answer, but when they disagree – they choose at random, the result is their (arithmetic) average 
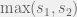
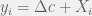
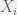


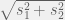


We can continue proposing even more strategies, but why not return to the experiment for the result? It was the last one: 
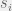
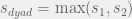
Two is a company, three is a crowd. (Generalizations and scaling)
 This framework is general and capable of dealing with any symmetric two-choice decision task (so called two-answers forced choice (2AFC)) whose difficulty can be varied. In [4] we generalize reference [2]’s models from a pair of interacting people to group of n people. Note that, the proposed strategies in [2] are by no means exhaustive. For example, once there is a group of three or more, people can cast votes. Also, one can consider model in which it may be hard to get the correct answer, but once one gets it, it is easy to demonstrate it to others (very loosely speaking, a human version of NP-hard problems). Additionally, when n is large it might be unfeasible to gather all information at once so we also study hierarchical information-aggregation, where only a few agents can interact at once. Considering more strategies and arbitrary n reveals a neat form of the result. All considered strategies [4] can be expressed in the following way:
This framework is general and capable of dealing with any symmetric two-choice decision task (so called two-answers forced choice (2AFC)) whose difficulty can be varied. In [4] we generalize reference [2]’s models from a pair of interacting people to group of n people. Note that, the proposed strategies in [2] are by no means exhaustive. For example, once there is a group of three or more, people can cast votes. Also, one can consider model in which it may be hard to get the correct answer, but once one gets it, it is easy to demonstrate it to others (very loosely speaking, a human version of NP-hard problems). Additionally, when n is large it might be unfeasible to gather all information at once so we also study hierarchical information-aggregation, where only a few agents can interact at once. Considering more strategies and arbitrary n reveals a neat form of the result. All considered strategies [4] can be expressed in the following way:
![\Large s_{group}(s_1, \ldots, s_n) = c \times n^\alpha \times \sqrt[\beta]{ \frac{s_1^\beta + \ldots + s_n^\beta}{n} }](https://s0.wp.com/latex.php?latex=%5CLarge+s_%7Bgroup%7D%28s_1%2C+%5Cldots%2C+s_n%29+%3D+c+%5Ctimes+n%5E%5Calpha+%5Ctimes+%5Csqrt%5B%5Cbeta%5D%7B+%5Cfrac%7Bs_1%5E%5Cbeta+%2B+%5Cldots+%2B+s_n%5E%5Cbeta%7D%7Bn%7D+%7D+&bg=f0f0f0&fg=555555&s=0&c=20201002)
were 
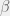

![\sqrt[\beta]{ (s_1^\beta + \ldots + s_n^\beta)/n }](https://s0.wp.com/latex.php?latex=%5Csqrt%5B%5Cbeta%5D%7B+%28s_1%5E%5Cbeta+%2B+%5Cldots+%2B+s_n%5E%5Cbeta%29%2Fn+%7D&bg=f0f0f0&fg=555555&s=0&c=20201002)
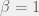

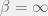
 For example, for voting the strategy function is:
For example, for voting the strategy function is:

The two opposite regime are “everyone is equal” (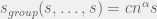

Some strategies assume a specific structure of the problem, but Voting and Best Decides can be used for any problem (in the later, we need to assume that there is feedback or another reliable way of deciding who is the most competent). In this case, depending on the distribution of individual performances, we can either perform voting or adhere to the opinion if the most skilled individual.
Further remarks
Collective decision-making is an important and prevalent activity, working at various scales. In some sense you can look at democracy, as (an alleged) wisdom of crowds. However, it is unlikely that there is one universal result covering all types of intellectual collaboration. Also, in the models investigated in [4] groups do no worse that their members ( 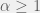
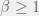
Further, it is not unlikely that apart from problem solving skills, there are collaboration or information-aggregation skills. A good example is the case of Kasparov vs the World in the Reinventing Discovery.
One cannot exclude other factors based purely on perception, information-sharing or optimal decision-making. Working in a group may provide additional stimulation (or distraction), and can influence motivation. Especially as the groups gets bigger, participants might be less motivated – see Ringelmann effect. Conformity may also play an important role — people are usually not eager to reject other decisions too often, as e.g in the Asch conformity experiment. Furthermore, in some cases there might be incentive to mislead others (e.g. in zero-sum games), so that misinformation gets amplified.
A fascinating question is: how does performance scale in real-world situations? For example: having a group of n programmers unlikely make the progress n times faster. I asked it on Programmers.SE, while I am still writing it. Additionally, when it comes to the performance of scientific groups, it turns about that there is a strong benefit from collaboration [5] (and other links from Does 2x bigger mean 2x better?).
And last not least, not only size matters. As with the perceptual task, collaboration technique is crucial, with the emphasis on communication. It has real-world implications – for example, when there are two programmers, they can work separately or do so-called pair-programming (working on a single computer). While initially the later may look as waste of resources, in many cases it turns out to be more efficient, for work and learning alike [6-7].
References
[1] Rauhut, Heiko, and Jan Lorenz. 2010. “The Wisdom of Crowds in One Mind: How Individuals Can Simulate the Knowledge of Diverse Societies to Reach Better Decisions.” Journal of Mathematical Psychology (November 19). doi:10.1016/j.jmp.2010.10.002.
[2] Bahrami, B., K. Olsen, P. E. Latham, A. Roepstorff, G. Rees, and C. D. Frith. 2010. “Optimally Interacting Minds.” Science 329 (5995) (August): 1081–1085. doi:10.1126/science.1185718.
[3] Sorkin, Robert D, Christopher J Hays, and Ryan West. 2001. “Signal-detection Analysis of Group Decision Making.” Psychological Review 108 (1): 183–203. doi:10.1037/0033-295X.108.1.183.
[4] Migdał, P., Rączaszek-Leonardi, J., Denkiewicz, M., & Plewczynski, D. (2012). Information-Sharing and Aggregation Models for Interacting Minds. Journal of Mathematical Psychology, 56 (6), 417-426 DOI: 10.1016/j.jmp.2013.01.002 arXiv: 1109.2044.
[5] Kenna, R., and B. Berche. 2010. “Critical Mass and the Dependency of Research Quality on Group Size.” Scientometrics 86 (2) (September 5): 527–540. doi:10.1007/s11192-010-0282-9, arXiv:1006.0928.
[6] McDowell, C., L. Werner, H. Bullock, and J. Fernald. 2002. “The Effects of Pair-Programming on Performance in an Introductory Programming Course.” ACM SIGCSE Bulletin 34 (1) (March 1): 38. doi:10.1145/563517.563353.
[7] Hannay, J. E., Dybå, T., Arisholm, E., & Sjøberg, D. I. (2009). The effectiveness of pair programming: A meta-analysis. Information and Software Technology, 51(7): 1110-1122. doi:10.1016/j.infsof.2009.02.001, PDF.


Pingback: Cataloging a year of blogging: the philosophical turn | Theory, Evolution, and Games Group
Pingback: Radicalization, expertise, and skepticism among doctors & engineers: the value of philosophy in education | Theory, Evolution, and Games Group