Evolutionary economics and game theory
May 3, 2013 4 Comments
Like the agents they study, evolutionary economics is highly heterogeneous. Models are ad-hoc and serve as heuristic guides to specific problems. This is similar to theoretical biology, where evolutionary models are independent of each other. Even the general theory of inclusive fitness does not provide a non-controversial unifying framework. Although there is no single framework, evolutionary economists are united by four main assumptions about the world:
- The world is constantly changing. Qualitative change is common, and fundamentally different from the
quantifiable gradual change that can be studied with standard equilibrium approaches - The generation of novelty is an important agent of economic change. The generation of this novelty is fundamentally unpredictable.
- Economic systems are complex systems; emergent properties, and non-linear and chaotic interactions put fundamental limits of prediction. Generation of novelty and complexity make evolutionary change irreversible.
- Human institutions and social arrangements emerge through self-organization and undesigned order. However, there is no agreement on if market or the emergence of state are more fundamental.
Nelson and Winter, the founders of modern evolutionary economics, define a theory as “a tool of inquiry” and distinguish between two types of theories: appreciative and formal. An appreciative theory is characterized by a broad process of analysis and understanding, with a ‘focus on the endeavour in which the theoretical tools are applied’, including engagement with empirical data. In contrast, a formal theory focuses on “improving or extending or corroborating the tool itself”.
For me, this definition of theory is not consist with what I consider the usual use of the word. In common language, or in the precise sense of Popper, a theory is something that can be invalidated or falsified. A tool cannot be falsified, it can only be bad or inconvenient for a task. Thus, in my distinction between theory and framework (or maybe in Kuhn’s words: paradigm), Nelson and Winter’s definition would fall under framework. However, it does not fully specify a framework, but only the process by which the framework is used. Hence, I would refer to what they call ‘theory’ as a process paradigm. We then have two categories of process paradigms: the appreciative process and the formal process.
If I understand Nelson and Winter correctly, then a scientist practicing the appreciative process is primarily concerned with describing a specific phenomena, or answering a specific question. She pursues this goal with any tools at her disposal only with the constraint of matching or fitting whatever is considered as empirical fact in her paradigm. This pragmatic approach reminds me of two very distinct groups: people that provide verbal descriptive theories (say much of psychology) on the one hand, and engineers on the other hand. I find it curious that such different fields would fall under one roof, and I think a further distinction of the appreciative process paradigm is needed: descriptive versus predictive.
A scientist with the formal process paradigm is concerned with building, connecting, refining, and testing theories. I find myself usually in this camp; I am primarily concerned with theories for the sake of theories, how they relate to each other, and if or how they can be best tested. Of course, most frameworks combine an element of both appreciative and formal process paradigms.
For Hodgson and Huang (2012), evolutionary economists primarily focus on the appreciative process and evolutionary game theorists on the formal. This marks some fundamental incompatibilities between the two approaches, but the authors believe them to be reconcilable. They suggest that EGT models can be used within EE as heuristic guides.
I think that Hodgson and Huang’s (2012) main fault is not acknowledge the power of abstraction. The primary skill of a computer scientist is knowing how to look at a problem and figure out what central concepts need to be preserved in an abstraction and which can be ignored. Once an abstract theory is present then whatever results are necessities in that theory will translate down into any concrete models. This allows you to study “simple” abstract models and establish truths about any model that has to embed the abstraction as a part of it. It gives you a way to study possible theories.
Unfortunately, little of EGT is done by computer scientists. Most models only relate to others through a verbal theory, and as such general abstract statements are difficult. However, I think there are families of models (say games on graphs) that could lend themselves to abstract analysis. If EGT pursues this avenue then it will be an extremely valuable tool for EE; it will allow them to make general abstract statements and prove theorems of the sort that are usually purvey of neoclassical economics.
![]() Hodgson, G., & Huang, K. (2010). Evolutionary game theory and evolutionary economics: are they different species? Journal of Evolutionary Economics, 22 (2), 345-366 DOI: 10.1007/s00191-010-0203-3
Hodgson, G., & Huang, K. (2010). Evolutionary game theory and evolutionary economics: are they different species? Journal of Evolutionary Economics, 22 (2), 345-366 DOI: 10.1007/s00191-010-0203-3

 ). The number of viable systems also increase, since I have yet to introduce a bias against complexity. In the figure, blue are the viable systems, while dashed lines for the 1-systems represent the space of unviable 1-systems.
). The number of viable systems also increase, since I have yet to introduce a bias against complexity. In the figure, blue are the viable systems, while dashed lines for the 1-systems represent the space of unviable 1-systems. is large, there is enough arrows emanating from the top red dot (instead of the one arrow in the previous figure) that one of them is likely to hit the viable blues in the 1-systems. At that point, this particular form of increase in complexity will cease.
is large, there is enough arrows emanating from the top red dot (instead of the one arrow in the previous figure) that one of them is likely to hit the viable blues in the 1-systems. At that point, this particular form of increase in complexity will cease. made up linearly arranged components drawn from
made up linearly arranged components drawn from  has a tiny probability
has a tiny probability  of being viable. There is no correlation among viable systems,
of being viable. There is no correlation among viable systems,  probability). Each operation resets
probability). Each operation resets  and the result of any operation has
and the result of any operation has  and
and  respectively. Let the system at time
respectively. Let the system at time 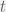 be
be  . At each timestep, some operating is performed on
. At each timestep, some operating is performed on  . If
. If  that
that 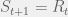 , else
, else 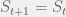 . Since the only role that
. Since the only role that  .
. :
: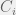 results in
results in  ,
, results in
results in 

 , where
, where  is viable.
is viable. .
. time,
time, 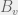 . Let’s say this happens at time
. Let’s say this happens at time 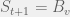 . However, since this changes nothing complexity-wise, we shall not consider it for now.
. However, since this changes nothing complexity-wise, we shall not consider it for now.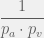 time. Let this happen at
time. Let this happen at  . Then at
. Then at  , we have
, we have  .
. , or mutate
, or mutate  time. This will be the most common event, since the chance of resulting in a viable
time. This will be the most common event, since the chance of resulting in a viable  are both very low. In fact,
are both very low. In fact,  must spend
must spend 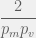 time as itself before it is likely to discover a viable
time as itself before it is likely to discover a viable  before it discovers a viable
before it discovers a viable  times before we have a good chance of discovering a viable
times before we have a good chance of discovering a viable 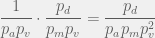
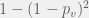 probability that at least one of
probability that at least one of 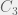 and
and 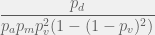 .
. or
or 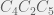 , in which all single deletions (for
, in which all single deletions (for  ,
,  , and
, and 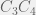 ) are all unviable.
) are all unviable. (or
(or  time. The chance the mutated component will itself be independently viable is
time. The chance the mutated component will itself be independently viable is 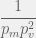 . To reach
. To reach 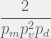
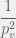 time. It takes
time. It takes  to discover the viable 3-system
to discover the viable 3-system  , it then takes
, it then takes  time to reach one of
time to reach one of  time. We must therefore discover viable 3-systems
time. We must therefore discover viable 3-systems  times before we have a good chance of discovering a viable 3-system that is locked-in and cannot quickly lose a component, yet remain viable. In total, we need
times before we have a good chance of discovering a viable 3-system that is locked-in and cannot quickly lose a component, yet remain viable. In total, we need
 are all relatively large numbers (at least compared to
are all relatively large numbers (at least compared to  , of
, of  , the probability of viability upon an edit.
, the probability of viability upon an edit. (the size or cardinality of
(the size or cardinality of  as
as  . Removing a component results in either
. Removing a component results in either  . The probability that at least one of them is viable is
. The probability that at least one of them is viable is  , which for
, which for  possible mutations. For as long as
possible mutations. For as long as  , this line of reasoning is possible. In fact, it is possible until
, this line of reasoning is possible. In fact, it is possible until 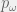 of being highly fit. Let
of being highly fit. Let  be the average size of the set of all mutants of any phenotype. For example, if n is the number of genes and the only mutations we consider are the loss-of-function of single genes, then
be the average size of the set of all mutants of any phenotype. For example, if n is the number of genes and the only mutations we consider are the loss-of-function of single genes, then 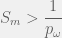 . Later extensions also consider cases where highly fit phenotypes exist in clusters and showed that percolation is still easily achievable (Gavrilets’ book
. Later extensions also consider cases where highly fit phenotypes exist in clusters and showed that percolation is still easily achievable (Gavrilets’ book  . What fraction of these combinations are highly fit? The answers must be a truly ridiculously small number. So small that if
. What fraction of these combinations are highly fit? The answers must be a truly ridiculously small number. So small that if 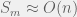 , I would imagine that there is no way that highly fit phenotypes reach percolation.
, I would imagine that there is no way that highly fit phenotypes reach percolation. , that is a wholly different matter altogether. For example,
, that is a wholly different matter altogether. For example,  for continuous traits in a simple model. If n is in the tens of thousands, my intuition tells me it’s possible that higly fit phenotypes reach percolation, since exponentials make really-really-really big numbers really quickly. Despite well known evidence that humans really are terrible intuiters at giant and tiny numbers, the absence of fitness valleys becomes at least plausible. But… it might not matter, because:
for continuous traits in a simple model. If n is in the tens of thousands, my intuition tells me it’s possible that higly fit phenotypes reach percolation, since exponentials make really-really-really big numbers really quickly. Despite well known evidence that humans really are terrible intuiters at giant and tiny numbers, the absence of fitness valleys becomes at least plausible. But… it might not matter, because:
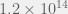 generations. The total number of bacteria sampled across all evolution is therefore on the order of
generations. The total number of bacteria sampled across all evolution is therefore on the order of 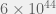 . Does that sound like a large number? Because it’s not. That’s the trouble with linear growth. Against
. Does that sound like a large number? Because it’s not. That’s the trouble with linear growth. Against  (where we consider
(where we consider 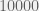 to be n, the dimension number),
to be n, the dimension number), 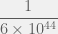 of the phenotype space, else we’ll never discover it. Is
of the phenotype space, else we’ll never discover it. Is  , where the fittest phenotype has relative fitness
, where the fittest phenotype has relative fitness  . This further dramatizes the inability of evolution to strike on “highly fit” phenotypes through a single mutation in realistic population size and time, since we must consider not
. This further dramatizes the inability of evolution to strike on “highly fit” phenotypes through a single mutation in realistic population size and time, since we must consider not  , where
, where  , where
, where  is the
is the  trait, and a mutation from
trait, and a mutation from  results in
results in  ), such that
), such that  is a random small number that can be negative, and the Euclidean distance between
is a random small number that can be negative, and the Euclidean distance between  and
and  , where
, where 

Eukaryotes without Mitochondria and Aristotle’s Ladder of Life
May 13, 2016 by Artem Kaznatcheev 2 Comments
In 348/7 BC, fearing anti-Macedonian sentiment or disappointed with the control of Plato’s Academy passing to Speusippus, Aristotle left Athens for Asian Minor across the Aegean sea. Based on his five years[1] studying of the natural history of Lesbos, he wrote the pioneering work of zoology: The History of Animals. In it, he set out to catalog the what of biology before searching for the answers of why. He initiated a tradition of naturalists that continues to this day.
Aristotle classified his observations of the natural world into a hierarchical ladder of life: humans on top, above the other blooded animals, bloodless animals, and plants. Although we’ve excised Aristotle’s insistence on static species, this ladder remains for many. They consider species as more complex than their ancestors, and between the species a presence of a hierarchy of complexity with humans — as always — on top. A common example of this is the rationality fetish that views Bayesian learning as a fixed point of evolution, or ranks species based on intelligence or levels-of-consciousness. This is then coupled with an insistence on progress, and gives them the what to be explained: the arc of evolution is long, but it bends towards complexity.
In the early months of TheEGG, Julian Xue turned to explaining the why behind the evolution of complexity with ideas like irreversible evolution as the steps up the ladder of life.[2] One of Julian’s strongest examples of such an irreversible step up has been the transition from prokaryotes to eukaryotes through the acquisition of membrane-bound organelles like mitochondria. But as an honest and dedicated scholar, Julian is always on the lookout for falsifications of his theories. This morning — with an optimistic “there goes my theory” — he shared the new Kamkowska et al. (2016) paper showing a surprising what to add to our natural history: a eukaryote without mitochondria. An apparent example of a eukaryote stepping down a rung in complexity by losing its membrane-bound ATP powerhouse.
Read more of this post
Filed under Commentary, Technical Tagged with Biology, complexity, current events, empirical, evolution, irreversibility, single cell organisms, supply driven evolution, video