February 5, 2013
by Artem Kaznatcheev
We have just started the 18th month for this blog, and this post is to celebrate this anniversary and the passing of a milestone: this is the 51st post! It is also to share some statistics about the blog, partially because I wish other bloggers would share theirs (as benchmarks or aspirations for people like me that enjoy metrics too much) and so that I can quickly refer to them later.
When I first launched this blog, I had the ambitious goal of having two posts a week, but in the back of my mind kept the more realistic target of creating one post a week. Unfortunately, even the modest goal has not been met with an average of ~2.9 posts a month. Most importantly, it has been hard to keep a regular schedule with large post-less gaps like 2011/10/13 – 2012/01/10, 2012/03/29 – 2012/05/13, 2012/07/23 – 2012/10/11, and the most recent 2012/12/04 – 2013/01/23. How do you keep yourself on a regular blogging schedule? How do you balance blogging with things “that pay the bills” such as school work and research?

Monthly viewership statistics for TheEGG.
Surprisingly enough, it was during one of these gaps that I realized that this blog can actually reach people. In the first 9 months of activity, the blog received a total of 1806 views. In June and July, I started cross-listing more heavily on researchblogging and the viewership jumped up to 996 (June) and 1108 (July). On August 23rd, somebody shared on Reddit my July 23rd Programming Playground post. The share resulted in a flood of 2146 views on that day alone, and brought August up to 4628 views. This is a significant fraction of the 16751 views that the blog received so far.
After this realization, I started promoting the blog on Reddit, although never as successfully as this first share. The self-share that generated the most traction and insightful comments was my critique of Chaitin’s “Proving Darwin”. This was the one post I noticed circulating through twitter, G+, and tumblr. However, most of the interest seemed to stem from the novelty of Chaitin’s book rather than my critique.
Overall, in terms of sites driving traffic here, Reddit leads by a long shot with 5146 views, followed by search engines with 2707, and then a more tightly spaced list: researchblogging (251), Facebook (240), Twitter (245), and scoop.it (137). That being said, I don’t really understand how WordPress collects these views statistics. For instance, if I was to trust researchblogging’s view statistics then they say that they drove 5514 views to TheEGG, with some posts having more clicks from researchblogging than total number of views (from all sources) recorded for those posts by wordpress. Unless 19/20ths of the people get lost between clicking on a link on researchblogging and arriving at WordPress then there is some big discrepancy with how the two sites record views. Can anybody more familiar on web analytics fill me in?
In terms of WordPress viewership, the top 5 posts are:
- Programming playground: A whole-cell computational model (2863)
- Is Chaitin proving Darwin with metabiology? (2195)
- How would Alan Turing develop biology? (1319)
- Marcel’s Generating random k-regular graphs (1012), and
- Marcel’s Spatial Structure (559)
On the other hand, the researchblogging stats tend to have less spread and correlate more closely with age:
- Tom’s Fewer Friends, More Cooperation (485)
- How would Alan Turing develop biology? (418)
- Can we expand our moral circle towards an empathic civilization? (397)
- Bifurcation of cooperation and inviscid ethnocentrism (385)
- Is Chaitin proving Darwin with metabiology? (331)
The primary goal of this blog remains as a way to foster collaboration, and as a companion to the EGT reading group that I host. The reading group is resuming next week after a hiatus. If you have suggestions for what to read, please email them to me or leave them as comments. In terms of collaboration, I am happy to say that 22% of the posts on the blog thus far have come from my colleagues and co-authors: Julian Z. Xue (6 posts), Marcel Montrey (3 posts), and Thomas R. Shultz (2 posts). I am very thankful for their contribution and encouragement, and I hope they will continue to participate in this blog. In the coming months, I am also trying to recruit some new faces with four potential new contributors expressing interest. If you would like to write a guest post about evolutionary game theory, mathematical or computational approaches to evolution, or agent-based modeling in general then let me know!
I look forward to the adventure of the next 50 posts with you.


 and
and 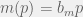 . After a long meeting with Robert a few month ago, I think that these were misleading payoffs to consider. I jotted these notes after the meeting, but forgot to release them on the blog. Instead, you get to enjoy them now while I refresh my memory.
. After a long meeting with Robert a few month ago, I think that these were misleading payoffs to consider. I jotted these notes after the meeting, but forgot to release them on the blog. Instead, you get to enjoy them now while I refresh my memory.






Why academics should blog and an update on readership
March 18, 2014 by Artem Kaznatcheev 13 Comments
It’s that time again, TheEGG has passed a milestone — 150 posts under our belt!– and so I feel obliged to reflect on blogging plus update the curious on the readerships statistics.
About a month ago, Nicholas Kristof bemoaned the lack of public intellectuals in the New York Times. Some people responded with defenses of the ‘busy academic’, and others agreement but with a shift of conversation medium to blogs from the more traditional media Kristof was focused on. As a fellow blogger, I can’t help but support this shift, but I also can’t help but notice the conflation of two very different notions: the public intellectual and the public educator.
Read more of this post
Filed under Commentary, Meta Tagged with collaboration, Daniel Dennett, mathematical oncology, Paul Feyerabend, research tools, stackexchange