To escape the Montreal cold, I am visiting the Sunshine State this week. I’m in Tampa for Moffitt’s 3rd annual integrated mathematical oncology workshop. The goal of the workshop is to lock clinicians, biologists, and mathematicians in the same room for a week to develop and implement mathematical models focussed on personalizing treatment for a range of different cancers. The event is structured as a competition between four teams of ten to twelve people focused on specific cancer types. I am on Javier Pinilla-Ibarz, Kendra Sweet, and David Basanta‘s team working on chronic myeloid leukemia. We have a nice mix of three clinicians, one theoretical biologist, one machine learning scientist, and five mathematical modelers from different backgrounds. The first day was focused on getting modelers up to speed on the relevant biology and defining a question to tackle over the next three days. Read more of this post
George E. P. Box is famous for the quote: “all models are wrong, but some are useful” (Box, 1979). A statement that many modelers swear by, often for the wrong reasons — usually they want preserve their pet models beyond the point of usefulness. It is also a statement that some popular conceptions of science have taken as foundational, an unfortunate choice given that the statement — like most unqualified universal statements — is blatantly false. Even when the statement is properly contextualized, it is often true for trivial reasons. I think a lot of the confusion around Box’s quote comes from the misconception that there is only one type of modeling or that all mathematical modelers aspire to the same ends. However, there are (at least) three different types of mathematical models.
In my experience, most models outside of physics are heuristic models. The models are designed as caricatures of reality, and built to be wrong while emphasizing or communicating some interesting point. Nobody intends these models to be better and better approximations of reality, but a toolbox of ideas. Although sometimes people fall for their favorite heuristic models, and start to talk about them as if they are reflecting reality, I think this is usually just a short lived egomania. As such, pointing out that these models are wrong is an obvious statement: nobody intended them to be not wrong. Usually, when somebody actually calls such a model “wrong” they actually mean “it does not properly highlight the point it intended to” or “the point it is highlighting is not of interest to reality”. As such, if somebody says that your heuristic model is wrong, they usually mean that it’s not useful and Box’s defense is of no help. Read more of this post
Fairly early in my course on Computational Psychology, I like to discuss Box’s (1979) famous aphorism about models: “All models are wrong, but some are useful.” Although Box was referring to statistical models, his comment on truth and utility applies equally well to computational models attempting to simulate complex empirical phenomena. I want my students to appreciate this disclaimer from the start because it avoids endless debate about whether a model is true. Once we agree to focus on utility, we can take a more relaxed and objective view of modeling, with appropriate humility in discussing our own models. Historical consideration of models, and theories as well, should provide a strong clue that replacement by better and more useful models (or theories) is inevitable, and indeed is a standard way for science to progress. In the rapid turnover of computational modeling, this means that the best one could hope for is to have the best (most useful) model for a while, before it is pushed aside or incorporated by a more comprehensive and often more abstract model. In his recent post on three types of mathematical models, Artem characterized such models as heuristic. It is worth adding that the most useful models are often those that best cover (simulate) the empirical phenomena of interest, bringing a model closer to what Artem called insilications. Read more of this post
[B]iology is primarily chemo-computation, chemical information systems and computational hardware.
Theoretical comp sci is the only field that is actually specifically dedicated to studying the mathematics / logic of computation. Therefore, although biology is an incredibly hard programming problem (only a fool thinks nature simple), it is indeed more about programming and less about the hardware it’s running on.
Although it is an easy stance for a theoretician to take, it is a little bit more involved for a molecular biologist, chemist, or engineer. Yet for the last 30 years, even experimentalists have been captivated by this computational realism and promise of engineering molecular devices (Drexler, 1981). Half a year ago, I even reviewed Bonnet et al. (2013) taking steps towards building transcriptors. They are focusing on the hardware side of biological computation and building a DNA-analogue of the von Neumann architecture. However, what we really need is a level of abstraction: a chemical programming language that can be compiled into biocompatible reactions. Read more of this post
One of the three goals of natural algorithms is to implement computers in non-electronic media. In cases like quantum computing, the goal is to achieve a qualitatively different form of computing, but other times (as with most biological computing) the goal is just to recreate normal computation (or a subset of it) at a different scale or in more natural ways. Of course, these two approaches aren’t mutually exclusive! Imagine how great it would be if we could grow computers on the level of cells, or smaller. For starters, this approach could revolutionize health-care: you could program some of your own cells to sense and record your internal environment and release drugs only when necessary. It could also alter how we manufacture things; if you throught 3D printers are cool, what if you could program nanoscale assemblies? Read more of this post
I often think of myself as an applied mathematician — I even spent a year of grad school in a math department (although it was “Combinatorics and Optimization” not “Applied Math”) — but when the giant systems of ODEs or PDEs come a-knocking, I run and hide. I confine myself to abstract or heuristic models, and for the questions I tend to ask these are the models people often find interesting. These models are built to be as simple as possible, and often are used to prove a general statement (if it is an abstraction) that will hold for any more detailed model, or to serve as an intuition pump (if it is a heuristic). If there are more than a handful of coupled equations or if a simple symmetry (or Mathematica) doesn’t solve them, then I call it quits or simplify.
However, there is a third type of model — an insilication. These mathematical or computational models are so realistic that their parameters can be set directly by experimental observations (not merely optimized based on model output) and the outputs they generate can be directly tested against experiment or used to generate quantitative predictions. These are the domain of mathematical engineers and applied mathematicians, and some — usually experimentalists, but sometimes even computer scientists — consider these to be the only real scientific models. As a prototypical example of an insilication, think of the folks at NASA numerically solving the gravitational model of our solar system to figure out how to aim the next mission to Mars. These models often have dozens or hundreds (or sometimes more!) coupled equations, where every part is known to perform to an extreme level of accuracy. Read more of this post
This Tuesday, I gave the second of two presentations for the EGT Reading group, both focused on the theory of group selection. Though I am currently working outside of academia, it has been a pleasure to pursue my interests in ecology, and our group discussions have proven to be both enjoyable and challenging.
The first presentation [pdf] is a review of a 2011 paper written by Marshall. It argues that when the models underlying inclusive fitness theory (IFT) and group selection are formally identical. However, as I tried to show during the presentation, this formal equivalency only holds for one specific type of group selection – group selection as the partitioning of selection between groups from selection within groups. It no longer holds when we consider the more restrictive definition of group selection as “natural selection on groups” in strict analogy to individual selection (this, incidentally, is the definition of group selection I gave in my last blog post)
Marshall J.A.R. (2011). Group selection and kin selection: formally equivalent approaches, Trends in Ecology & Evolution, 26 (7) 325-332. DOI: 10.1016/j.tree.2011.04.008
The second presentation [pdf] is a review of a paper by Paulsson (2002). That paper presents an interesting case of multi-level (group) selection, where the “individuals” are plasmids – self-replicating gene clusters in the cytoplasm of procaryotes – and the “groups” are the plasmid-hosting cells. It’s a nice illustration of the basic dilemma that drives group selection. Inside a cell, plasmids which replicate faster have an advantage over their cell mates. But cells in which plasmids replicate too fast grow slower. Thus, at the level of individuals selfishness is favored, but at the level of groups altruism is favored. Paulsson’s paper explains the mechanisms of plasmid replication control; sketches up models of intra- and inter-cellular selection gradients; and explains how conflicts between individual- and group-selection are resolved by plasmids. He also considers a third level of selection on lineages, but both Artem and I were confused about what exactly Paulsson meant.
Paulsson, J. (2002). Multileveled selection on plasmid replication. Genetics, 161(4): 1373-1384.
We have previously discussed the finicky task of defining intelligence, but surely being able to do math qualifies? Even if the importance of mathematics in science is questioned by people as notable as E.O. Wilson, surely nobody questions it as an intelligent activity? Mathematical reasoning is not necessary for intelligence, but surely it is sufficient?
Note that by mathematics, I don’t mean number crunching or carrying out a rote computation. I mean the bread and butter of what mathematicians do: proving theorems and solving general problems. As an example, consider the following theorem about metric spaces:
Nearly a year ago, the previous post in this series introduced a way for programmers to play around with biology: a model that simulated the dynamics of a whole cell at unprecedented levels of details. But what if you want to play with the real thing? Can you program a living cell? Can you compute with molecular biology?
Could this single-celled photosynthetic algae be your next computer?
Biology inspired computation can probably be traced back as far back as Turing’s (1948) introduction of B-Type neural networks. However, the molecular biology approach is much more recent with Adleman (1994) proposing DNA computing, and Păun (2000) introducing membrane computing with P-systems. These models caused a stir when they appeared due to the ease of misrepresenting their computational power. If you allow the cells or membranes to carry on exponential rate of reproduction for an arbitrarily long time, then these systems can solve NP-complete problems quickly. In fact, it is not hard to show that this model would allow you to solve PSPACE-complete problems. Of course, in any reasonable setting, your cells can only grow at an exponential rate until they reach the carrying capacity of the environment you are growing them in. If you take this into account then efficient DNA and membrane computing are no more powerful than the usual definition of efficient computation — polynomial time on a Turing machine.
The stirred (i.e. inviscid) nature of membrane and (early approaches to) DNA computing provide substantial constraints for empirical realizations, and scalability of bio-computing. In these early models, regulatory molecules are reused in the self-mixing environment of the cell, and gates correspond to chemical reactions. As such, gates are temporary; and the information carrying molecule must change at every step of the computation to avoid being confused with residue from the previous step. This made implementing some gates such as XNOR — output 1 only if both inputs are the same — experimentally impossible (Tamsir, 2011): how would you tell which input is which and how would the gate know it has received both inputs and not just an abnormally high concentration of the first?
To overcome this, Bonnet et al. (2013) designed a cellular computation model that more closely resembles the von Neumann architecture of the device you are reading this post on. In particular, they introduced a cellular analog of the transistor — the transcriptor. The whimsical name comes from the biology process they hijacked for computation, instead of electric current flowing on copper wires the researchers looked at the “transcriptional current” of RNA polymerase on DNA “wires”. Only if a control signal is present does the transcriptor allow RNA polymerase to flow through it; otherwise it blocks them, just like an electric transistor. By putting several transcriptors together, and choosing their control signals, Bonnet et al. (2013) can implement any logic gate (including the previously unrealized NXOR) just as an electrical engineer would with transistors. What matters most for connecting to quantum computing, is the ability to reliably amplify logical signals. With amplifying gates like AND, OR, and XOR, the authors were able to produce more than a 3-fold increase in control signal. For further details on the transcriptor listen to Drew Endy explain his group’s work:
Taking inspiration from biology is not restricted to classical computation. Vlatko Vedral provides a great summary of bio-inspired quantum computing; start from top down, figure out how biology uses quantum effects at room temperature and try to harness them for computation. The first step here, is to find a non-trivial example of quantum effects in use by a biological system. Conveniently, Engel et al. (2007) showed that photosynthesis provides such an example.
During photosynthesis, an incident photon becomes an ‘exciton’ that has to quickly walk through a maze of interconnected chlorophyll molecules to find a site where its energy can be used to phosphorylate used-up ADP into energy-carrying ATP. Unfortunately, if the exciton follows a classical random walk (i.e. spreads out in proportion to the square root of time) then it cannot reach a binding site before decaying. How does biology solve this? The exciton follows a quantum walk! (Rebentrost et al., 2009)
It is cool to know that we can observe a quantum walk, but can that be useful for computation? My former supervisor Andrew Childs (2009; see also Childs et al., 2013) is noted for showing that if we have control over the Hamiltonian defining our quantum walk then we can use the walk to do universal computation. Controlling the Hamiltonian generating a quantum walk is analogous to designing a graph for a classical walk. Theoretical work is still needed to bridge Rebentrost et al. and Childs, since (as Joe Fitzsimons pointed out on G+) the biological quantum walk is not coherent, and the decoherence that is present might doom any attempt at universal computation. The last ingredient that is needed is a classic controller.
Since the graph we need will depend on the specific problem instance we are trying to solve, we will need a classical computer to control the construction of the graph. This is where I hope synthetic biology results like Bonnet et al. (2013) will be useful. The transcriptors could be used as the classic control with which a problem instance is translated into a specific structure of chlorophyll molecules on which a quantum walk is carried out to do the hard part of the computation. The weak quantum signal from this walk can then be measured by the transcriptor-based controller and amplified into a signal that the experimenter can observe on the level of the behavior (say fluorescence) of the cell. Of course, this requires a ridiculous amount of both fundamental work on quantum computing, and bio-engineering. However, could the future of scalable quantum computers be in the noisy world of biology, instead of the sterility of superconductors, photon benches, or ion-traps?
References
Adleman, L. M. (1994). Molecular computation of solutions to combinatorial problems. Science, 266(5187), 1021-1023.
Childs, A. M. (2009). Universal computation by quantum walk. Physical review letters, 102(18), 180501. [ArXiv pdf]
Childs, A. M., Gosset, D., & Webb, Z. (2013). Universal Computation by Multiparticle Quantum Walk. Science, 339(6121), 791-794. [ArXiv pdf]
Engel GS, Calhoun TR, Read EL, Ahn TK, Mancal T, Cheng YC et al. (2007). Evidence for wavelike energy transfer through quantum coherence in photosynthetic systems. Nature 446 (7137): 782–6.
Păun, G. (2000). Computing with membranes. Journal of Computer and System Sciences, 61(1), 108-143.
Rebentrost, P., Mohseni, M., Kassal, I., Lloyd, S., & Aspuru-Guzik, A. (2009). Environment-assisted quantum transport. New Journal of Physics, 11(3), 033003. [ArXiv pdf]
Tamsir, A., Tabor, J. J., & Voigt, C. A. (2011). Robust multicellular computing using genetically encoded NOR gates and chemical/wires/’. Nature, 469(7329), 212-215.
Canadian veterans and the Royal Canadian Legion at Remembrance Day ceremonies on Lower Field of McGill University (November 11th, 2012). Photographed and arranged by Adam Scotti; reproduced with permission.
Remembrance Day is a time to reflect on past conflicts and honour the men and women that did not return home from war. The day commemorates the armistice signed on the morning on November 11th, 1918 to formally end the hostilities of the First World War “at the 11th hour of the 11th day of the 11th month”. It is observed by a minute of silence to honour the fallen in all armed conflicts. It is difficult for me to trace my genealogy past the Russian Civil War and draw any personal connection to the First World War. But like many Russians, war losses are a looming memory as none of my great-grandfathers returned home from the Second World War. However, even with careful memory of past conflicts, it seems that we are not capable of avoiding new ones.
In a typical high-school history text, one will see WW1 attributed to nationalism. This is a form of tag-based ethnocentrism, where the arbitrary tag is nationality — a slippery concept for formal definitions but one for which many of us have an intuitive grasp from cultural indoctrination. Of course, nationality seems like a very high-level tag, with many arbitrary distinctions possible to separate people within a single nation (to take a recently prominent one: political party allegiance). As such, our concerns about the expansion of the moral circle apply just as well to nationality as they do to all of humanity. If we understood how the in-group expands from a family, clan, or tribe to the nation, we would be most of the way to an emphatic civilization. The only hurdle would be to understand what the permanent absence of an out-group entails. For now, I will leave the issues of connecting tribe-level ethnocentrism to nationalism at the level of analogy.
A popular approach in understanding nationalism and war is to trace it to a potential evolutionary origin. Usually, this means understanding how tribal ethnocentrism and warfare could have emerged in late Pleistocene and early Holocene humans. Choi and Bowles (2007) take this approach through an agent based group-selection model. Agents form groups (or tribes) of three generations, with each generation consisting of 26 individuals. As far as I can tell, only one of the three generations reproduces and participates in interactions. Each individual is either an altruist or not (in-group strategy), and parochial or tolerant (out-group strategy). Within the tribe, a public-goods game is played with altruists cooperating and nonaltruists defecting. Reproduction is pseudosexual (individuals don’t have sexes, but are still paired to produce offspring) and proportional to the fitness of both parents with full recombination (the in-group and out-group strategies are at two independent loci) and a small probability of mutation and a small random migration rate between groups.
Between the groups, the authors employ a very complicated mechanism. All 20 groups are paired randomly to interact, each group has a probability equal to the group’s fraction of tolerant agents to choose a non-hostile interaction. If both groups choose to be non-hostile, then each tolerant agent gets a benefit from each tolerant agent of the other group. If either group is hostile, then there is a chance of war equal to the difference in proportion of parochial altruists (warriors) between the groups (). If war does not occur, then there is still no benefit to tolerant agents, and the individual payoff is completely from the in-group game. If war occurs, then a constant fraction of parochial altruists perish (14%) regardless of if the war is a tie (with probability ) or the side with more PAs is victorious. If the stronger group is victorious, then they kill a fraction of of the weaker group’s civilians. The authors do not make clear what happens when , but presumably there is a floor effect and every member of group is killed. The stronger group (both civilians and parochial altruists) then produces the offspring to repopulate the losing group.
In the above model there are two stable equilibria. In one there is about 15% of both in-group altruism, and out-group parochialism, and in the other there is 85% of each. In the first equilibrium there is very little war and hostility, in the second it abounds, but at levels that are not unreasonable given the archaeological data. Transitions can happen between these equilibria relatively quickly (around 200 cycles, or 5000 years for human generations). The long term average tends to populations that are either parochial altruists or tolerant non-altruists, with very little in-between. From this, Choi & Bowles (2007) conclude the co-evolution of parochial altruism and war.
This paper caused a stir when it came out, and has been heavily cited. From a modeling perspective, I think it suffers from numerous flaws (most introduced in the arbitrary and complicated war mechanism) and could be approached cleaner analytically, but I will save the details of my critique for a future posts. The main achievement of Choi and Bowles (2007) is an attempt to be more realistic that the abstract models typically studied in evolutionary game theory, and to reinforce the important point that hostility and altruism often go hand in hand. Especially in the case of ethnocentrism, it is important to remember the dangers in the cooperation it brings. As I wrote in 2010 in the context of a different model:
The evolution of ethnocentrism … is a double-edged sword: it can cause unexpected cooperative behavior, but also irrational hostility.
Choi JK, & Bowles S (2007). The coevolution of parochial altruism and war. Science (New York, N.Y.), 318 (5850), 636-40 PMID: 17962562
 To escape the Montreal cold, I am visiting the Sunshine State this week. I’m in Tampa for Moffitt’s 3rd annual integrated mathematical oncology workshop. The goal of the workshop is to lock clinicians, biologists, and mathematicians in the same room for a week to develop and implement mathematical models focussed on personalizing treatment for a range of different cancers. The event is structured as a competition between four teams of ten to twelve people focused on specific cancer types. I am on Javier Pinilla-Ibarz, Kendra Sweet, and David Basanta‘s team working on chronic myeloid leukemia. We have a nice mix of three clinicians, one theoretical biologist, one machine learning scientist, and five mathematical modelers from different backgrounds. The first day was focused on getting modelers up to speed on the relevant biology and defining a question to tackle over the next three days.
To escape the Montreal cold, I am visiting the Sunshine State this week. I’m in Tampa for Moffitt’s 3rd annual integrated mathematical oncology workshop. The goal of the workshop is to lock clinicians, biologists, and mathematicians in the same room for a week to develop and implement mathematical models focussed on personalizing treatment for a range of different cancers. The event is structured as a competition between four teams of ten to twelve people focused on specific cancer types. I am on Javier Pinilla-Ibarz, Kendra Sweet, and David Basanta‘s team working on chronic myeloid leukemia. We have a nice mix of three clinicians, one theoretical biologist, one machine learning scientist, and five mathematical modelers from different backgrounds. The first day was focused on getting modelers up to speed on the relevant biology and defining a question to tackle over the next three days.

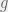 from each tolerant agent of the other group. If either group is hostile, then there is a chance of war equal to the difference in proportion of parochial altruists (warriors) between the groups (
from each tolerant agent of the other group. If either group is hostile, then there is a chance of war equal to the difference in proportion of parochial altruists (warriors) between the groups (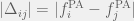 ). If war does not occur, then there is still no benefit to tolerant agents, and the individual payoff is completely from the in-group game. If war occurs, then a constant fraction of parochial altruists perish (14%) regardless of if the war is a tie (with probability
). If war does not occur, then there is still no benefit to tolerant agents, and the individual payoff is completely from the in-group game. If war occurs, then a constant fraction of parochial altruists perish (14%) regardless of if the war is a tie (with probability 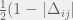 ) or the side with more PAs is victorious. If the stronger group is victorious, then they kill a fraction of
) or the side with more PAs is victorious. If the stronger group is victorious, then they kill a fraction of  of the weaker group’s civilians. The authors do not make clear what happens when
of the weaker group’s civilians. The authors do not make clear what happens when  , but presumably there is a floor effect and every member of group
, but presumably there is a floor effect and every member of group  is killed. The stronger group (both civilians and parochial altruists) then produces the offspring to repopulate the losing group.
is killed. The stronger group (both civilians and parochial altruists) then produces the offspring to repopulate the losing group.

Are all models wrong?
November 6, 2013 by Artem Kaznatcheev 46 Comments
In my experience, most models outside of physics are heuristic models. The models are designed as caricatures of reality, and built to be wrong while emphasizing or communicating some interesting point. Nobody intends these models to be better and better approximations of reality, but a toolbox of ideas. Although sometimes people fall for their favorite heuristic models, and start to talk about them as if they are reflecting reality, I think this is usually just a short lived egomania. As such, pointing out that these models are wrong is an obvious statement: nobody intended them to be not wrong. Usually, when somebody actually calls such a model “wrong” they actually mean “it does not properly highlight the point it intended to” or “the point it is highlighting is not of interest to reality”. As such, if somebody says that your heuristic model is wrong, they usually mean that it’s not useful and Box’s defense is of no help.
Read more of this post
Filed under Commentary Tagged with philosophy of science, prediction, realistic model