March 29, 2013
by Yunjun Yang
Proponents of free markets often believe in an “invisible hand” that guides an economic system without external controls like government regulations. Therefore a highly efficient economic equilibrium can be created if all market participants act purely out of self-interest. In the paper titled “Individual versus systemic risk and the Regulator’s Dilemma.”, Beale et al. (2011) applied agent-based simulations to show that a system of financial institutions attempting to minimize their own risk of failure may not minimize the risk of failure of the entire system. In addition, the authors have suggested several ways to limit the financial institutions in order to lower the risk of failure for the financial system. Their suggestion responds directly to the regulatory challenges during the recent financial crisis where failures of some institutions have endangered the financial system and even the global economy.

It’s easy to get tangled up trying to regulate banks.
To illustrate the point of individual optimality versus the system optimality, the paper makes simple assumptions of the financial system and its participants. In a world of 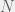 independent banks and
independent banks and  assets, each of the banks seeks to invest its resources into these assets from time 0 to time 1. The returns on assets are assumed to be independently and identically distributed following a student’s t-distribution with a degree of freedom of 1.5. If a bank’s loss exceeds a certain threshold, it fails. Due to this assumption, each bank’s optimal allocation (to minimize it’s chance of failure) is to invest equally in each asset.
assets, each of the banks seeks to invest its resources into these assets from time 0 to time 1. The returns on assets are assumed to be independently and identically distributed following a student’s t-distribution with a degree of freedom of 1.5. If a bank’s loss exceeds a certain threshold, it fails. Due to this assumption, each bank’s optimal allocation (to minimize it’s chance of failure) is to invest equally in each asset.
However, a regulator is concerned with the failure of the financial system instead of the failure of any individual bank. To incorporate this idea, the paper suggests a cost function for the regulator:  where
where  is the number of failed banks. This cost function is the only coupling between banks in the model. If
is the number of failed banks. This cost function is the only coupling between banks in the model. If  , this cost function implies each additional bank failure “costs” the system more (one can tell by taking the derivative
, this cost function implies each additional bank failure “costs” the system more (one can tell by taking the derivative 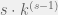 , which is an increasing function in if ). As
, which is an increasing function in if ). As  increases from 1, the systematic optimal allocation of all the banks starts to deviate further away from the individual optimal allocation of the banks. When is 2, the systematic optimal allocation for each bank is to invest entirely in one asset, a drastic contrast to the individual optimal allocation (investing equally in each asset). In this situation, the safest investment allocation for the system leads to the riskiest investment allocation for the individual bank.
increases from 1, the systematic optimal allocation of all the banks starts to deviate further away from the individual optimal allocation of the banks. When is 2, the systematic optimal allocation for each bank is to invest entirely in one asset, a drastic contrast to the individual optimal allocation (investing equally in each asset). In this situation, the safest investment allocation for the system leads to the riskiest investment allocation for the individual bank.
While the idea demonstrated above is interesting, the procedure is unnecessarily complex. The assumption of student t distribution with degree of freedom of 1.5 is far too broad of an assumption for the distribution of financial assets. However, the distribution does not have the simplicity of Bernoulli or Gaussian distributions to arrive at analytical solutions (See Artem’s question on toy models of asset returns for more discussion). One simple example would be bonds whose principal and coupon payments of the bond are either paid to the bondholder in full or partially paid in the event of a default. Therefore bond is not close to a t-distribution. Other common assets such as mortgages and consumer loans are not t-distribution either. Therefore the assumption of t-distribution does not come close to capturing the probabilistic nature of many major financial assets. The assumption of t-distribution does not provide any additional accuracy to simpler assumptions of Gaussian or Bernoulli distributions. Assumption of Gaussian distribution or Bernoulli distributions, on the other hand, is at least capable of providing analytical solutions without the tedious simulations.
The authors define two parameters  and
and 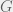 in an attempt to constrain the banks to have systematically optimal allocations. denotes the average distance of asset allocations between each pair of banks. denotes the distance between the average allocations across banks and the individual optimal allocation. When is increasing from 1, it was found that bank allocations with a higher and a near-zero are best for the system. To show the robustness of these two parameters, the authors varied other parameters such as number of assets, number of banks, the distributions of the assets, correlation between the assets, and the form of the regulator’s cost function. They found lower systematic risk for the banking system by enforcing a near zero and higher . This result implies that the banks should concentrate in their own niche of financial assets, but the aggregate system should still have optimal asset allocations.
in an attempt to constrain the banks to have systematically optimal allocations. denotes the average distance of asset allocations between each pair of banks. denotes the distance between the average allocations across banks and the individual optimal allocation. When is increasing from 1, it was found that bank allocations with a higher and a near-zero are best for the system. To show the robustness of these two parameters, the authors varied other parameters such as number of assets, number of banks, the distributions of the assets, correlation between the assets, and the form of the regulator’s cost function. They found lower systematic risk for the banking system by enforcing a near zero and higher . This result implies that the banks should concentrate in their own niche of financial assets, but the aggregate system should still have optimal asset allocations.
Based on the paper, it may appear that the systematic risk of failure can be reduced in the financial system by controlling for parameters and (though without analytical solutions). Such controls have to be enforced by an omnipotent “regulator” with perfect information on the exact probabilistic nature of the financial products and the individual optimal allocations. Moreover, this “regulator” must also have unlimited political power to enforce its envisioned allocations. This is far from reality. Financial products are different in size and riskiness, and there is continuous creation of new financial products. Regulators such as the Department of Treasury, SEC, and Federal Reserve also have very limited political power. For example, these regulators were not legally allowed to rescue Lehman Brothers whose failure led to the subsequent global credit and economic crisis. The entire paper can be boiled down to one simple idea: optimal actions for the individuals might not be optimal for the system, but if there is an all-powerful regulator who forces the individuals to act optimally for the system, the system will be more stable. This should come as no surprise to regular readers of this blog, since evolutionary game theory deals with this exact dilemma when looking for cooperation. This main result is rather trivial, but opens ideas for more realistic simulations. One idea would be to remove or weaken the element of “regulator” and add incentives for banks to act more systematically optimal. It would be interesting to look at how banks can act under these circumstances and whether or not their actions can lead to a systematically optimal equilibrium.
One key aspect of a systematic failure is not the simultaneous failure of many assets. There are two important aspects of bank operations. Banks operate by taking funding from clients to invest in riskier assets. This operation requires strong confidence in the bank’s strength to avoid unexpected withdrawals or the ability to sell these assets to pay back the clients. Secondly banks obtain short-term loans from each other by putting up assets as collateral. This connects the banks more strongly than a simple regulator cost function, creating a banking ecosystem.
The strength of the inter-bank connections depends on value of the collateral. In the event of catastrophic losses of subprime loans by some banks, confidence in these banks are shaken and the value of assets start to come down. A bank’s clients may start to withdraw their money and the bank sells its assets to meet its clients’ demands, further depressing the prices of the assets sometimes leading to a fire sale. Other banks would start asking for more and higher quality collateral due to the depressed prices from the sell-off. The bank’s high-quality assets and cash may subsequently become strained leading to further worry about the bank’s health and more client withdrawals and collateral demands. Lack of confidence in one bank’s survival leads to worries about the other banks that have lent to that bank triggering a fresh wave of withdrawals and collateral demands. Even healthy banks can be ruined in a matter of days by a widespread panic.
As a result, the inter-bank dealings are instrumental in the event of systematic failure. Beale et al. (2011) intentionally sidestepped this inter-bank link to arrive at their result purely from a perspective of asset failure. But, the inter-bank link was the most important factor in creating mass failure of the financial system. It is because of this link that failure of one asset (subprime mortgages) managed to nearly bring down the financial systems in the entire developed world. Not addressing the inter-bank link is simply not addressing the financial crisis at all.
 Beale N., Rand D.G., Battey H., Croxson K., May R.M. & Nowak M.A. (2011). Individual versus systemic risk and the Regulator’s Dilemma, Proceedings of the National Academy of Sciences, 108 (31) 12647-12652. DOI: 10.1073/pnas.1105882108
Beale N., Rand D.G., Battey H., Croxson K., May R.M. & Nowak M.A. (2011). Individual versus systemic risk and the Regulator’s Dilemma, Proceedings of the National Academy of Sciences, 108 (31) 12647-12652. DOI: 10.1073/pnas.1105882108



 with the assertion that it has no solutions for
with the assertion that it has no solutions for 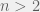 and
and  as positive integers. A statement that almost anybody can understand, but one that is far from easy to prove or even approach
as positive integers. A statement that almost anybody can understand, but one that is far from easy to prove or even approach



Allegory of the replication crisis in algorithmic trading
August 17, 2019 by Artem Kaznatcheev 1 Comment
One of the most interesting ongoing problems in metascience right now is the replication crisis. This a methodological crisis around the difficulty of reproducing or replicating past studies. If we cannot repeat or recreate the results of a previous study then it casts doubt on if those ‘results’ were real or just artefacts of flawed methodology, bad statistics, or publication bias. If we view science as a collection of facts or empirical truths than this can shake the foundations of science.
The replication crisis is most often associated with psychology — a field that seems to be having the most active and self-reflective engagement with the replication crisis — but also extends to fields like general medicine (Ioannidis, 2005a,b; 2016), oncology (Begley & Ellis, 2012), marketing (Hunter, 2001), economics (Camerer et al., 2016), and even hydrology (Stagge et al., 2019).
When I last wrote about the replication crisis back in 2013, I asked what science can learn from the humanities: specifically, what we can learn from memorable characters and fanfiction. From this perspective, a lack of replication was not the disease but the symptom of the deeper malady of poor theoretical foundations. When theories, models, and experiments are individual isolated silos, there is no inherent drive to replicate because the knowledge is not directly cumulative. Instead of forcing replication, we should aim to unify theories, make them more precise and cumulative and thus create a setting where there is an inherent drive to replicate.
More importantly, in a field with well-developed theory and large deductive components, a study can advance the field even if its observed outcome turns out to be incorrect. With a cumulative theory, it is more likely that we will develop new techniques or motivate new challenges or extensions to theory independent of the details of the empirical results. In a field where theory and experiment go hand-in-hand, a single paper can advance both our empirical grounding and our theoretical techniques.
I am certainly not the only one to suggest that a lack of unifying, common, and cumulative theory as the cause for the replication crisis. But how do we act on this?
Can we just start mathematical modelling? In the case of the replicator crisis in cancer research, will mathematical oncology help?
Not necessarily. But I’ll come back to this at the end. First, a story.
Let us look at a case study: algorithmic trading in quantitative finance. This is a field that is heavy in math and light on controlled experiments. In some ways, its methodology is the opposite of the dominant methodology of psychology or cancer research. It is all about doing math and writing code to predict the markets.
Yesterday on /r/algotrading, /u/chiefkul reported on his effort to reproduce 130+ papers about “predicting the stock market”. He coded them from scratch and found that “every single paper was either p-hacked, overfit [or] subsample[d] …OR… had a smidge of Alpha [that disappears with transaction costs]”.
There’s a replication crisis for you. Even the most pessimistic readings of the literature in psychology or medicine produce significantly higher levels of successful replication. So let’s dig in a bit.
Read more of this post
Filed under Commentary Tagged with current events, ethics and morality, finance, metamodeling, philosophy of science