January 31, 2012
by Artem Kaznatcheev
“When should I stop my simulation?” is one of the basic questions that comes up frequently when working with simulations. The question is especially relevant when you are running hundreds or thousands of trials. If the parameter settings are well understood, then sometimes you might have an intuition or analytic reason for not needing to look past a certain length of runs. However, when the point of your work is to understand the parameter space, then you often don’t have this luxury.
I first came across this problem in 2010 when working on my paper “Robustness of ethnocentrism to changes in inter-personal interactions” [pdf, slides] for Complex Adaptive Systems – AAAI Fall Symposium. Since I was looking at the whole space of two-player two-strategy games, there was a huge variability in the system dynamics. In particular, the end of transient behavior of pre-saturated world and the onset of a stable behavior in the post-saturated world varied with the parameters. Since I was up against a deadline, I did not worry too much about this issue, ran my simulations for 3000 time steps, and hoped that the transient behavior was over by that time (it was from a visual inspection of the results after collecting them). Last year, in starting to think about the journal version of the paper, I realized that I should think more carefully about how to test for when I should running my simulations while I am running them.
I quickly realized that the question applies to a much broader setting than my specific simulations. A good algorithm or sound heuristic for this problem could be used in all kinds of simulation settings. Of particular appeal would be a less ad-hoc neuron recruitment criteria for cascade-correlation neural networks or general stopping condition for learning algorithms. Hoping for a quick, simple, and analytically sound solution for this problem, I asked it on the cross validated and, more recently, computational sciences stackexchanges. I also discussed it with Tom Shultz in hopes of insights from exiting stopping criteria in neural net literature. Unfortunately, there does not seem to be a simple answer to this, and most of the current algorithms use very naive and ad-hoc techniques. Since my statistics knowledge is limited, Tom decided to run this question past the quantitative psychologists at McGill. Tom and I will be presenting the question to them this Thursday.
General question
The question can be stated either in terms of time-series or dynamic systems, and I state it in both ways on the two stackexchanges. Since I understand very little about statistics, I prefer the dynamic systems version. I also think this version makes more sense to folks that run simulations, and my original application.
When working with simulations of dynamical systems and I often track a single parameter  , such as the number of agents (for agents based models) or the error rate (for neural networks). This parameter usually has some interesting transient behavior. In my agent based models it corresponds to the initial competition in the pre-saturated world, and in neural networks it corresponds to learning. The type and length of this behavior depends on the random seed and simulation parameters. However, after the initial transient period, the system stabilizes and has small (in comparison to the size of the changes in the transient period) thermal fluctuations $\sigma$ around some mean value $x^*$. This mean value, and the size of thermal fluctuations depends on the simulation parameters, but not on the random seed, and are not known ahead of time. I call this the stable state (or maybe more accurately the stochastic stable state) and Tom likes to call it the asymptote.
, such as the number of agents (for agents based models) or the error rate (for neural networks). This parameter usually has some interesting transient behavior. In my agent based models it corresponds to the initial competition in the pre-saturated world, and in neural networks it corresponds to learning. The type and length of this behavior depends on the random seed and simulation parameters. However, after the initial transient period, the system stabilizes and has small (in comparison to the size of the changes in the transient period) thermal fluctuations $\sigma$ around some mean value $x^*$. This mean value, and the size of thermal fluctuations depends on the simulation parameters, but not on the random seed, and are not known ahead of time. I call this the stable state (or maybe more accurately the stochastic stable state) and Tom likes to call it the asymptote.
The goal is to have a good way to automatically stop the simulation once it has transitioned from the initial transient period to the stable state. We know that this transition will only happen once, and the transient period will have much more volatile behavior than the stable state.
Naive approach
The naive approach that first poped into my mind (which I have also seen used as win conditions for some neural networks, for instance) is to pick to parameters 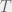 and
and 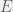 , then if for the last timesteps there are not two points and
, then if for the last timesteps there are not two points and  such that
such that 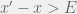 then we conclude we have stabilized. This approach is easy, but not very rigorous. It also forces me to guess at what good values of and should be. It is not obvious that guessing these two values well is any easier than simply guessing the stop time (like I did in my lazy approach by guessing a stop time of 3000 time steps).
then we conclude we have stabilized. This approach is easy, but not very rigorous. It also forces me to guess at what good values of and should be. It is not obvious that guessing these two values well is any easier than simply guessing the stop time (like I did in my lazy approach by guessing a stop time of 3000 time steps).
After a little though, I was able to improve this naive approach slightly. We can use a time and confidence parameter  and assume a normal distribution on the error. This will save us the effort of knowing the size of thermal fluctuations.
and assume a normal distribution on the error. This will save us the effort of knowing the size of thermal fluctuations.
Let  be the change in the time series between timestep
be the change in the time series between timestep 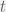 and
and  . When the series is stable around
. When the series is stable around 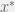 ,
,  will fluctuate around zero with some standard error. Take the last ,
will fluctuate around zero with some standard error. Take the last , 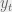 ‘s and fit a Gaussian with confidence using a function like Matlab’s normfit. The fit will give us a mean
‘s and fit a Gaussian with confidence using a function like Matlab’s normfit. The fit will give us a mean  with confidence error on the mean
with confidence error on the mean 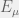 and a standard deviation
and a standard deviation  with corresponding error
with corresponding error  . If
. If 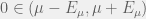 , then you can accept. If you want to be extra sure, then you can also renormalize the s by the you found (so that you now have standard deviation 1) and test with the [Kolmogorov-Smirnov](http://www.mathworks.com/help/toolbox/stats/kstest.html) test at the confidence level, or one of the other strategies in this question.
, then you can accept. If you want to be extra sure, then you can also renormalize the s by the you found (so that you now have standard deviation 1) and test with the [Kolmogorov-Smirnov](http://www.mathworks.com/help/toolbox/stats/kstest.html) test at the confidence level, or one of the other strategies in this question.
Although the confidence level is an acceptable parameter, the window size is still a problem. I think this naive approach can be further refined by doing some sort of discounting of past events and looking at the whole history (instead of just the last timesteps). This would eliminate the need for but include a discounting scheme as a parameter. If we assume standard geometric discounting, this would not be too bad, but there is no reason to believe that this is a reasonable approach. Further, in the geometric approach the discounting factor will implicitly set a timescale and thus the parameter will be as hard to guess as T. The only advantage is that in this approach everything starts to look like machine learning. Maybe there is a known optimal discounting scheme, or at least some literature on good discounting schemes.
Auto-correlations and co-integration
A slightly more complicated approach proposed by some respondents is auto-correlation and co-integration. The basic idea of both is to look back at your time-series and consider how much it resembles itself. The idea is that the transient period will not resemble itself, and the stable state will not resemble the transient period, however the stable state will resemble itself. Thus, you should detect it via this methods. Unfortunately, they require more complicated tests and are still stuck with a rolling window parameter $T$. Thus, I do not understand their appeal over the refined naive approach.
Testing for structural change
This seems to be the approach by heavy-weight statistics. Unfortunately, I do not have a sufficient stats background to really judge the general suggestion on structural change or the change in error answer. However, there seems to be a statistics literature on detecting structural change. Testing for asymptotes and stability should fall within this literature, but I do not have a good grasp of it and hope that I will gain insights from comments on this post and the presentation on Thursday. For now, I just know that I should be looking closely at the Cross Validated tags on structural-change and change-point. Unfortunately, to detect change points it seems that I need to have a good statistical model of the process that is generating my time-series. Which brings us to the last “answer”: I am not specifying my model with enough detail.
Transient and stable states are ill-defined
In an answer on scicomp, David Ketcheson points out that I do not supply a clear enough definition of transient and stable behavior. The easiest way to see my lack of clear definition is that even if I was offered several tools for detecting asymptotes and stability, I don’t have a criteria to decide which tool is best. I have been suspecting that it would come down to this, and unfortunately have been a bad computer scientists and have not hunkered down to make a general formal model for asking my question. If no better alternatives are suggested on Thursday or in the comments, then I will start to model my system as a POMDP with one strongly connected component that starts somewhere outside this component and eventually decays into it.
The moral of the story: statistics does not magically solve all problems.





Plato and the working mathematician on Truth and discourse
December 1, 2018 by Artem Kaznatcheev 1 Comment
Plato’s writing and philosophy are widely studied in colleges, and often turned to as founding texts of western philosophy. But if we went out looking for people that embraced the philosophy — if we went out looking for actual Platonist — then I think we would come up empty-handed. Or maybe not?
A tempting counter-example is the mathematician.
It certainly seems that to do mathematics, it helps to imagine the objects that you’re studying as inherently real but in a realm that is separate from your desk, chair and laptop. I am certainly susceptible to this thinking. Some mathematicians might even claim that they are mathematical platonists. But there is sometimes reasons to doubt the seriousness of this claim. As Reuben Hersh wrote in Some Proposals for Reviving the Philosophy of Mathematics:
What explains this discrepency? Is mathematical platonism — or a general vague idealism about mathematical objects — compatible with the actual philosophy attributed to Plato? This is the jist of a question that Conifold asked on the Philosophy StackExchange almost 4 years ago.
In this post, I want to revisit and share my answer. This well let us contrast mathematical platonism with a standard reading of Plato’s thought. After, I’ll take some helpful lessons from postmodernism and consider an alternative reading of Plato. Hopefully this PoMo Plato can suggest some fun thoughts on the old debate on discovery vs invention in mathematics, and better flesh out my Kantian position on the Church-Turing thesis.
Read more of this post
Filed under Commentary, Preliminary Tagged with algorithmic philosophy, philosophy of math, philosophy of mind, stackexchange