Irreversible evolution with rigor
October 13, 2011
by Julian Xue
We have now seen that man is variable in body and mind; and that the variations are induced, either directly or indreictly, by the same general causes, and obey the same general laws, as with the lower animals.
— First line read on a randomly chosen page of Darwin’s The Descent of Man, in the Chapter “Development of Man from some Lower Form”. But this post isn’t about natural selection at all, so that quote is suitably random.
The intuition of my previous post can be summarized in a relatively inaccurate but simple figure:

In this figure, the number of systems is plotted against the number of components. As the number of components increase from 1 to 2, the number of possible systems greatly increase, due to large size of the space of all components ( ). The number of viable systems also increase, since I have yet to introduce a bias against complexity. In the figure, blue are the viable systems, while dashed lines for the 1-systems represent the space of unviable 1-systems.
). The number of viable systems also increase, since I have yet to introduce a bias against complexity. In the figure, blue are the viable systems, while dashed lines for the 1-systems represent the space of unviable 1-systems.
If we begin at the yellow dot, an addition operation would move it to the lowest red dot. Through a few mutations — movement through the 2-system space — the process will move to the topmost red dot. At this red dot, losing a component is impossible, since losing a component would make it unviable. To lose a component, it would have to back mutate to the bottommost red dot, an event that, although not impossible, is exceedingly unlikely if is sufficiently large. This way, the number of components will keep increasing.
The number of components won’t increase without bound, however, as I said in my last post, once  is large, there is enough arrows emanating from the top red dot (instead of the one arrow in the previous figure) that one of them is likely to hit the viable blues in the 1-systems. At that point, this particular form of increase in complexity will cease.
is large, there is enough arrows emanating from the top red dot (instead of the one arrow in the previous figure) that one of them is likely to hit the viable blues in the 1-systems. At that point, this particular form of increase in complexity will cease.
I’d like to sharpen this model with a bit more rigor. First, however, I want to show a naive approach that doesn’t quite work, at least according to the way that I sold it.
Consider a space of systems  made up linearly arranged components drawn from . Among there are viable systems that are uniformly randomly distributed throughout ; any
made up linearly arranged components drawn from . Among there are viable systems that are uniformly randomly distributed throughout ; any  has a tiny probability
has a tiny probability  of being viable. There is no correlation among viable systems, is the only probability we consider. There are three operations possible on a system S: addition, mutation, and deletion. Addition adds a randomly chosen component from to the last spot in S (we will see that the spot is unimportant). Deletion removes a random component from S. Mutation mutates one component of S to another component in with uniformly equal probability (that is, any component can mutate to any other component with
of being viable. There is no correlation among viable systems, is the only probability we consider. There are three operations possible on a system S: addition, mutation, and deletion. Addition adds a randomly chosen component from to the last spot in S (we will see that the spot is unimportant). Deletion removes a random component from S. Mutation mutates one component of S to another component in with uniformly equal probability (that is, any component can mutate to any other component with  probability). Each operation resets
probability). Each operation resets  and the result of any operation has of being viable.
and the result of any operation has of being viable.
Time proceeds in discrete timesteps, at each timstep, the probability of addition, mutation, and deletion are  and
and  respectively. Let the system at time
respectively. Let the system at time 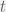 be
be  . At each timestep, some operating is performed on , resulting in a new system, call it
. At each timestep, some operating is performed on , resulting in a new system, call it  . If is viable, then there is a probability
. If is viable, then there is a probability  that
that 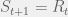 , else
, else 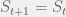 . Since the only role that plays is to slow down the process, for now we will consider
. Since the only role that plays is to slow down the process, for now we will consider  .
.
Thus, if  :
:
Removal of 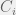 results in
results in  ,
,
Addition of a component  results in
results in 
Mutation of a component to another component results in 
Let the initial S be  , where
, where  is viable.
is viable.
Let be small, but  .
.
The process begins on , additions and mutations are possible. If no additions happen, then in approximately  time, mutates to another viable component,
time, mutates to another viable component, 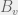 . Let’s say this happens at time . Since ,
. Let’s say this happens at time . Since , 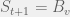 . However, since this changes nothing complexity-wise, we shall not consider it for now.
. However, since this changes nothing complexity-wise, we shall not consider it for now.
A successful addition takes approximates 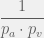 time. Let this happen at
time. Let this happen at  . Then at
. Then at  , we have
, we have  .
.
At this point, let us consider three possible events. The system can lose , lose  , or mutate . Losing results in a viable , and the system restarts. This happens in approximately
, or mutate . Losing results in a viable , and the system restarts. This happens in approximately  time. This will be the most common event, since the chance of resulting in a viable or going through mutation to become a viable
time. This will be the most common event, since the chance of resulting in a viable or going through mutation to become a viable  are both very low. In fact,
are both very low. In fact,  must spend
must spend 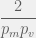 time as itself before it is likely to discover a viable through mutation, or
time as itself before it is likely to discover a viable through mutation, or  before it discovers a viable . The last event isn’t too interesting, since it’s like resetting, but with a viable instead of , which changes nothing (this lower bound is also where Gould’s insight comes from). Finding is interesting, however, since this is potentially the beginning of irreversibility.
before it discovers a viable . The last event isn’t too interesting, since it’s like resetting, but with a viable instead of , which changes nothing (this lower bound is also where Gould’s insight comes from). Finding is interesting, however, since this is potentially the beginning of irreversibility.
Since we need time as to discover , but each time we discover , it stays that way on average only time, we must discover  times before we have a good chance of discovering a viable . Since it takes for each discovery of a viable , in total it will take approximately
times before we have a good chance of discovering a viable . Since it takes for each discovery of a viable , in total it will take approximately
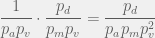
timsteps before we successfully discover . Phew. For small , we see that it takes an awfully long time before any irreversibility kicks in.
Once we discover a viable , there is 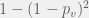 probability that at least one of
probability that at least one of 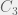 and are viable by themselves, in which case a loss can immediately kick in to restart the system again at a single component. The number of timesteps before we discover a viable in which neither are viable by themselves is:
and are viable by themselves, in which case a loss can immediately kick in to restart the system again at a single component. The number of timesteps before we discover a viable in which neither are viable by themselves is:
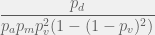 .
.
Unfortunatly this isn’t quite irreversibility. Now I will show that the time it takes for to reduce down to a viable single component is on the same order as what it takes to find viable  or
or 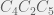 , in which all single deletions (for , the single deletions are:
, in which all single deletions (for , the single deletions are:  ,
,  , and
, and 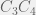 ) are all unviable.
) are all unviable.
We know that and are unviable on their own. Thus, to lose a component viably, must mutate to  (or ), such that (or ) is viable and is also independently viable. To reach a mutant of that is viable takes takes
(or ), such that (or ) is viable and is also independently viable. To reach a mutant of that is viable takes takes  time. The chance the mutated component will itself be independently viable is . Thus, the approximate time to find one of the viable systems or is
time. The chance the mutated component will itself be independently viable is . Thus, the approximate time to find one of the viable systems or is 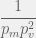 . To reach from there takes time, for a total of
. To reach from there takes time, for a total of
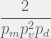
time. It’s quite easy to see that to go from to a three component system (either or ) such that a loss of a component renders the 3-system unviable, is also on the order of 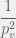 time. It takes
time. It takes  to discover the viable 3-system
to discover the viable 3-system  , it then takes
, it then takes  time to reach one of or (two thirds of all mutations will hit either or , of these mutation, are viable). Each time a viable 3-system is discovered, the system tends to stay there
time to reach one of or (two thirds of all mutations will hit either or , of these mutation, are viable). Each time a viable 3-system is discovered, the system tends to stay there  time. We must therefore discover viable 3-systems
time. We must therefore discover viable 3-systems  times before we have a good chance of discovering a viable 3-system that is locked-in and cannot quickly lose a component, yet remain viable. In total, we need
times before we have a good chance of discovering a viable 3-system that is locked-in and cannot quickly lose a component, yet remain viable. In total, we need

time. Since  are all relatively large numbers (at least compared to ), there is no “force” for the evolution of increased complexity, except the random walk force.
are all relatively large numbers (at least compared to ), there is no “force” for the evolution of increased complexity, except the random walk force.
In the next post, I will back up statements with simulations and see how this type of processes allows us to define different types of structure, some of which increases in complexity.



You really should find a way to describe this clearly and rigorously with pictures (don’t try to draw graphs of the type you sketch on whiteboards, but instead try a graph theory kind of graph with directed edges labeled by probabilities). I think this will make it easier for you to explain (and maybe even understand) your thoughts more clearly. You’ve presented this to me in person before, and yet I still couldn’t really follow the description in this post. If you are going to throw in random math-jargon, try to be complete with inequalities and such whenever you say something is smaller. Also avoid words like “much larger” or “very very small” unless you are making an approximation in that step (for instance, if you are making a first order approximation of something, you might say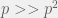 or some such to carry through your argument. Otherwise the words are just distracting.
or some such to carry through your argument. Otherwise the words are just distracting.
The most important comment I can make is to figure out where to be general and where not to be general. Could the gist of this had been described with binary strings WLOG? Or where could you have made obvious WLOG assumptions? I think I can see a few places. The best way to do this, I think, is to apply your ideas to concrete models instead of trying to talk about them abstractly.
Pingback: An update | Theory, Evolution, and Games Group