Machine learning and prediction without understanding
June 5, 2013 32 Comments
Big data is the buzzword du jour, permeating from machine learning to hadoop powered distributed computing, from giant scientific projects to individual social science studies, and from careful statistics to the witchcraft of web-analytics. As we are overcome by petabytes of data and as more of it becomes public, it is tempting for a would-be theorist to simply run machine learning and big-data algorithms on these data sets and take the computer’s conclusions as understanding. I think this has the danger of overshadowing more traditional approaches to theory and the feedback between theory and experiment.
Of course, I am not saying anything new, Chomsky has famously expressed his skepticism along similar lines with the prevalence of Machine Learning in linguistics research:
It’s true there’s been a lot of work on trying to apply statistical models to various linguistic problems. I think there have been some successes, but a lot of failures. There is a notion of success … which I think is novel in the history of science. It interprets success as approximating unanalyzed data.
In this case, though, it seems that Chomsky might be fighting a losing battle. A lot of the funding for research is driven by results and predictions, and — for many — understanding is just an inessential step in that process. In linguistics, this is best summarized by a quip attributed to Frederick Jelinek:
Every time I fire a linguist, the performance of our speech recognition system goes up.
Jelinek is referring to the advantage that purely statistical machine learning methods provide over explicit linguistic models. Coincidently, machine learning can also provide us with the tools to formally look at this debate. We can model learning a theory from data as proper learning: our real world is given by some real function 
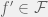
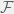
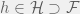
 Ishanu Chattopadhyay — the third speaker on the second day of the 2nd workshop on Natural Algorithms and the Sciences — considered a very natural variant on this idea. A common task in science is, given finite samples from two sources of data, to determine if the sources implement the same underlying noisy process or two different ones. Further, if the data is generated by two different processes then can we say how different these processes are? If you set one of your sources as your null hypothesis then this is equivalent to hypothesis testing
Ishanu Chattopadhyay — the third speaker on the second day of the 2nd workshop on Natural Algorithms and the Sciences — considered a very natural variant on this idea. A common task in science is, given finite samples from two sources of data, to determine if the sources implement the same underlying noisy process or two different ones. Further, if the data is generated by two different processes then can we say how different these processes are? If you set one of your sources as your null hypothesis then this is equivalent to hypothesis testing
Chattopadhyay, Wen, & Ray (2010) considered a processes that is governed by (or well approximated by) probabilistic finite state automata (PFSAs). We can think of this source as a PFSA inside black box: we can press a button that will generate a symbolic stream of observations but we cannot peek inside to see how the machine works. The authors also assume there are given a finite number of candidate PFSAs that they can examine as potential candidates for approximating the environment, their goal is to determine (in an online manner) , which candidate approximates the black box best and to what extent. Before they start receiving data from the black box, the authors use the candidate PFSAs to build annihilators that serve as a type of filter for the incoming data. The data that makes it through the filter is then compared to the simplest model that just outputs uncorrelated letters uniformly at random, and if it matches this behavior then the PSFA that generated this annihilator is a good approximation of the data.
More formally, the authors build an abelian group on the space of probability measures that induces a group structure on a restricted set of irreducible PFSAs. The restriction is fundamental since if this procedure worked for reducible PFSAs then it could be used to break the RSA cryptosystem — that secures all our online transactions — by the method of Kearns & Valiant (1994). The group operation corresponds to their annihilation procedure on data streams, the identity element in the null PFSA that generates symbols uniformly at random, and the inverse is computed during their preprocessing of the candidate PFSAs into annihilation procedures. The algorithm comes down to adding the unknown stream to inverses of the candidates in this abelian group and seeing if the result matches the identity. If the resulting stream (statistically) matches the identity then the inverted element must have been (a close approximation of) our unknown function.
The above procedure is efficient but inadvertently builds a PFSA representation of the original data — it provides some understanding. In his talk, Chattopadhyay showed that the procedure can be extended to the problem of comparing two data sources without first learning either one’s representation as a PFSA. We can compute the inverse directly on the raw stream data instead of first building a PFSA and then inverting it. Unfortunately, if we have 

This work has an obvious application in fields like finance, where a real model is impossible to come by. A trader can use old data to create the inverted stream annihilator and use it to annihilate new data tic-by-tic as it comes in to detect anomalies: the process suddenly shifting from its historic process to a new one. In the rest of his talk, Chattopadhyay stressed similar successes for his approach in other domains, and showed that it can match the behavior of much more carefully constructed understanding-rich models of anomaly detection in domains like the detection of gravitational waves.
If we can skip understanding and just get quick results, then why bother with theory and analytic treatments? It is tempting to say that more data and statistical analysis can’t possibly hurt (except maybe the opportunity cost of collecting it), they just give more playthings for theorists. But for me, the real problem is that a focus on data changes priorities. Scientists (due mostly to science funding) start to move away from trying to explain and understand phenomena and more to collecting data and data-mining it to make predictions without understanding. A focus on blind statistics on big data often provides great practical results in the short term (and that is why it wins funding) at the expense of the understanding needed for long term development of science. In particular I suspect that after a short success it will produce a field that doesn’t know how to ask new and interesting questions. A field that must rely on continuing to mine slight variations on the same sort of data for harder and harder to find practical gems. Unfortunately, this social consideration is not built into our machine learning based analysis.
Note: this is the sixth (and last!) review blogpost of a series (1, 2, 3, 4, and 5) on the recent workshop on Natural Algorithms and the Sciences at Princeton’s Center for Computational Intractability. Still to come is a general overview post summarizing the six reviews and making them easier to navigate.
References
Chattopadhyay, Ishanu, Wen, Yicheng, & Ray, Asok (2010). Pattern Classification In Symbolic Streams via Semantic Annihilation of Information American Control Conference arXiv: 1008.3667v1
Kearns, M., & Valiant, L. (1994). Cryptographic limitations on learning Boolean formulae and finite automata. Journal of the ACM, 41(1), 67-95.
Pitt, L., & Valiant, L. G. (1988). Computational limitations on learning from examples. Journal of the ACM, 35(4), 965-984.


Roger Penrose would like a word with you.
I assume you are referring to Penrose’s silly insistence (in books like The Emperor’s New Mind) that the human mind is capable of reasoning beyond that of Turing machines. In that case, I suggest you reread the post since I do not suggest at any point that I believe that humans are capable (in theory) of something beyond machines. All I suggest is that standard approaches to machine learning (and especially ‘Big Data’) do not build a theory that is communicable to humans. That doesn’t mean this is not possible, in fact I have previously blogged about machines that communicate human understandable proofs.
Thanks for sharing my post on your tumblr, since you are interested in quantum computing you might enjoy this post. However, I would appreciate that if you decide to comment then you would make less ambiguous comments than this quip and the gif response you gave to Jacob’s careful comment below.
“I assume you are referring to Penrose’s silly insistence (in books like The Emperor’s New Mind) that the human mind is capable of reasoning beyond that of Turing machines.”
Nope. Good guess though. I’m just referring to his ideas about what it means to actually understand something.
“That doesn’t mean this is not possible”
I know. That’s why Google and NASA just bought a D-Wave.
“I would appreciate that if you decide to comment then you would make less ambiguous comments than this quip and the gif response you gave to Jacob’s careful comment below.”
You should be used to dealing with ambiguity…
I am not familiar with Penrose’s thoughts on this, can you recommend an article that summarizes his stance?
As you noticed with your reference to ambiguity, I tried to sidestep the issue of carefully explaining what I meant by understanding and instead relied on the reader having their own conception that might be adequately close to my own. I think it is too difficult of a definition to be given convincingly in a blog post and still match our everyday usage of the word. However, if pressed then I could try to give a definition in the context of computational learning theory. I would say a learning algorithm is capable of “understanding” if its hypotheses class is simple enough to have non-trivial meta-questions about hypotheses be decidable, i.e. there is not an analogue of Rice’s theorem for the class. With this definition, a hypotheses class of DFAs, PFSA, or MDPs could be considered as understanding, but one that allows arbitrary algorithms (as simple prediction does) would not be understanding because we cannot answer meta questions beyond generating a prediction.
I’m not sure how this comment is relevant. Bringing up D-Wave is just opening a whole other discussion about if they are doing a service to quantum computing or hurting the field. Although I work on quantum computing and enjoy talking about D-Wave, I’d rather not go into a detailed discussion here since it is off-topic. In case you haven’t already seen it, I would recommend Scott’s most recent post about D-Wave.
@Artem
“I am not familiar with Penrose’s thoughts on this, can you recommend an article that summarizes his stance?”
Even better. He did a whole lecture on it at The Googles: http://www.youtube.com/watch?v=f477FnTe1M0
“I’m not sure how this comment is relevant.”
You said
and I replied by referring to a machine that is ideal for sparse coding/SSFL stuff (so, the “algorithm(s)” behind human cognition). This is probably why Andrew Ng also got scooped up by them recently.
“I would recommend Scott’s most recent post about D-Wave.”
I wouldn’t.
I have an adjacent question to the main topic of your post regarding the concept you brought up of trying to determine whether the process inside of 2 different black boxes is the same by comparing their input-output responses. In compartmental modeling (http://en.wikipedia.org/wiki/Multi-compartment_model) there is a notion of input-output equivalency, where 2 or more distinct models have the exact same input-output, does this also occur in PFSA’s? If so, then wouldn’t there be still strength in RSA encryption as long as the underlying process has a set of various models that match it’s input-output relationship?
The hardness result for reducible PFSA follows from the fact that DFAs of the sort built by Kearns & Valiant to encode RSA can be expressed as reducible PFSAs. However, the model of learning is a little bit different from KV94 to the one used by CWR10, so my comment was mostly heuristic. That being said, KV94 is independent of representation so very friendly for black-box or improper learning, and matching on input-output (or even closely approximating) is enough.
I am not familiar with multi-compartment modeling (beyond what I can glean from the name and wikipedia article), so I can’t make a more intelligent reply. Sorry!
Two different PFSAs “can” generate exactly the same finite string (especially if both are strongly connected, and on the same alphabet). However, the probability that the strings match exponentially falls with string length. There are a number of ways to understand this… one way is to invoke the asymptotic equipartition property in information theory, and realize that “different” PFSAs have different typical sets. Also, PFSAs in the framework used in the above mentioned work does not have inputs. And Artem is correct in pointing out that the learning models used in Kearns’ construction (acyclic automata) and in the above are somewhat different.
Pingback: Friday Links | Meta Rabbit
Thanks for the post Artem.
I find that the bleak situation you describe – mining deeper and deeper and settling for prediction (if you even get that) rather than understanding – is one that is rife in cancer biology. We are faced with a problem of scales (nicely outlined by Philip Gerlee in his post here: http://p-gerlee.blogspot.com/2013/05/biological-levels-and-aim-of-cancer.html) that just MIGHT BE intractable. But, instead of focussing on fighting with the big questions (which could take a LONG TIME to solve) and trying to answer them rigorously, we instead buy whatever new shiny machine is out there and start measuring stuff. Measure what you ask? Anything will do, but we prefer genomic data. Why? Because there is LOTS of it. You can always find something that has a p-value of < 0.05 if you have 10,000 columns of data you are trying to associate with your clinical/biological outcome of choice. I don't mean to be cynical (oh, wait, yes I do), but I can't help it. There is a theory gap in cancer research AT LEAST 50 years wide, and we are caught up with the Red Queen, running as fast as we can just to stay in the same place.
I think we need to refocus entirely and stop being satisfied with the quick fix that we can get by culling questionably relevant conclusions from the piles of big data, and start over.
Apologies to the Red Queen for imperfectly applying her hypothesis.
Whenever people collect a ridiculously large amount of data and then establish some simple relationship, I just can’t stop and think of Ramsey theory. No matter how unstructured your graph is, if it is large enough then a simple highly-structured subgraph (or its highly structured dual) will appear somewhere in your data.
I wonder what the best way to tighten the gap between theory and experiment is for cancer research. For some reason, I suspect it is not through application of physics inspired mathematical reasoning. However, my reason for this belief is not based on an understanding of cancer, but because if it is as simple as applying tools from the theoretical physics toolbox then why hasn’t it already been done by physicists? However, that argument isn’t always valid, as the economist that doesn’t believe in $10 bills lost on the street knows.
Pingback: Toward an algorithmic theory of biology | Theory, Evolution, and Games Group
interesting writeups. an old debate on “understanding vs prediction” is the original invention of quantum mechanics at the turn of the last century, with similar positions. you seem to argue that there is some difference between a model created by a human versus one created by a computer. but really— at some level there is no difference whatsoever! somehow at the bottom this sounds like a false debate. it is true there is some difference in computational datamining approaches versus old methods of statistics, but the two are basically getting married as we speak. what are people lamenting? the loss of humanly-comprehensible models? now that may be more accurate. but that is the price of the complexity we are studying. complex phenomena, complex models. the computer also allows us to determine when complex models can be simplified, such as determining the optimal # of neurons in a neural network or the number of support vectors in an SVM etc…. so anyway, am just not really understanding the debate here, yet have seen multiple references to it elsewhere, and it would be helpful to know more refs on the subject.
I share similar concern (or caution?) about big data. I think the following two posts said it the best for me:
Big data – context = bad by Roger Peng
and The Hidden Biases in Big Data by Kate Crawford
Thank you for these links. Somehow I missed them when you first posted nearly two years ago. I really liked the quote selected by Roger Peng from Nick BIlton’s article:
This is often lost on computer scientists and the like, this became painfully painful to me after I blogged about the ethic of big data especially from the responses on /r/compsci.
Thank you for the article. Its very encouraging that I could get across some of the key ideas within the 30 min, especially since time didnt permit going into the math much. Of course I do have a difference of opinion on the role of data-driven learning in science; but then my views are probably biased on the subject. I would like to point out that “data smashing” is not reported in the paper that you cited (CWR2010), although some of the ingredients are there (the abelian structure for example). In particular, i do not need to assume a “finite number of candidate PFSAs” (that was indeed the case in the 2010 paper), but we can relax that assumption, where no a priori knowledge of any models or family of models is required (as long as the generating processes are ergodic and stationary or nearly so). The paper is under review currently, and I will post a link when it comes out.
Great work in pointing out that extension to reducible PFSAs would be impossible due to Kearn’s hardness result, and that it would imply breaking RSA.
I enjoyed your talk, and it was great to see you at the workshop. If you want a refresher on all the other talks, then there is an overview here.
The post on your work has generated the most traffic so far. I was worried that I buried your results too deeply in my aimless philosophical wanderings, so I am glad to know that the spirit came across. I apologize for the confused attributions between the paper and talk. I tried to recreate the gist of your argument from my notes and your old paper, I didn’t include all the details I could gather because I try to keep the blog light on math and I wasn’t sure how much of your talk you wanted to be public.
However, my supervisors (Prakash and Doina) and I are pretty interested in your result. Can you send me a preprint of your forthcoming paper? My address is firstname(dot)lastname(at)mail(dot)mcgill(dot)ca. If you are ever in the Montreal area send me an email and I will see if I can arrange for you to talk on this paper to our ML folks.
Pingback: Monoids, weighted automata and algorithmic philosophy of science | Theory, Evolution, and Games Group
Pingback: Stats 101: an update on readership | Theory, Evolution, and Games Group
Pingback: Cataloging a year of blogging: the algorithmic world | Theory, Evolution, and Games Group
Pingback: A Fistful of Computational Philosophy
Pingback: From heuristics to abductions in mathematical oncology | Theory, Evolution, and Games Group
Pingback: Why academics should blog and an update on readership | Theory, Evolution, and Games Group
Pingback: Cross-validation in finance, psychology, and political science | Theory, Evolution, and Games Group
Pingback: Weapons of math destruction and the ethics of Big Data | Theory, Evolution, and Games Group
Pingback: Limits of prediction: stochasticity, chaos, and computation | Theory, Evolution, and Games Group
Pingback: Cytokine storms during CAR T-cell therapy for lymphoblastic leukemia | Theory, Evolution, and Games Group
Pingback: Radicalization, expertise, and skepticism among doctors & engineers: the value of philosophy in education | Theory, Evolution, and Games Group
Pingback: Description before prediction: evolutionary games in oncology | Theory, Evolution, and Games Group
Pingback: Blogging community of computational and mathematical oncologists | Theory, Evolution, and Games Group
Pingback: Process over state: Math is about proofs, not theorems. | Theory, Evolution, and Games Group