Computer science on prediction and the edge of chaos
May 24, 2013 12 Comments
With the development of statistical mechanics, physicists became the first agent-based modellers. Since the scientists of the 19th century didn’t have super-computers, they couldn’t succumb to the curse of computing and had to come up with analytic treatments of their “agent-based models”. These analytic treatments were often not rigorous, and only a heuristic correspondence was established between the dynamics of macro-variables and the underlying microdynamical implementation. Right before lunch on the second day of the Natural Algorithms and the Sciences workshop, Joel Lebowitz sketched how — for some models — mathematical physicists still continue their quest to rigorously show that macrodynamics fatefully reproduce the aggregate behavior of the microstates. In this way, they continue to ask the question: “when can we trust our analytic theory and when do we have to simulate the agents?”
What are the fundamental constraints on prediction? Theoretical computer scientists are probably the best equipped to answer this question in the general case. The day before Lebowitz, Cris Moore held the position of standing between the workshop participants and their lunch. He used this opportunity to explain how physics, the problem of prediction, and computational complexity relate. In computational complexity, we study what sort of problems can be solved with a limited resource such as time, space, communication, or even randomness. To start us off on the road to prediction vs. simulation, Moore considered the question of parallelization vs. serial processing (
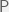




In the last talk of day one, Mark Braverman considered two more obstacles to prediction: chaos and universality. Chaos theory is a well developed field of complexology that is familiar to physicists and biologists, and its limits of prediction rely on the high variance in behavior between paths with similar initial conditions. To exactly describe the behavior of a chaotic system over any significant time-horizon, the initial conditions have to be extremely well measured. In computer science terms: the initial measurement needs an exponential amount of precision in the time-horizon to which we want to predict the system. This is why we can’t predict the exact weather in a specific location to a high degree of accuracy more than a few days in the future. However, we are seldom interested in this level of precision from our models, usually we mean something else by prediction. A typical prediction might be: if we keep pumping greenhouses gasses into the atmosphere then in 100 years it will be on average far warmer on the planet. Chaotic systems do not place any fundamental constraints on such qualitative predictions, in fact they often have easy to describe long-term qualitative behavior. Universal systems pose more of a challenge.
Rice’s theorem states that for any non-trivial property (i.e. one that isn’t constant on all languages), there is no algorithm that decides if the language of a given Turning Machine satisfies that property. For natural algorithms, this means that if your model is universal (there is a way to use the initial conditions and parameters of your model to encode an arbitrary Turing Machine) then, in general, even qualitative statements about the long-term behavior of your system are impossible. If you are a modeler, and you built a model that is universal then you’ve simply built in too much freedom, you can recreate anything and predict nothing. As with Moore, there are problems in the gap: undecidable models that are too unstructured to encode arbitrary Turing machines and thus not universal, but still not restricted enough to be predictable.
Universality of models is not uncommon, Bernad Chazelle‘s influence systems from the opening remarks can display both chaos and universality. In Chazelle’s model of diffusive systems, agents keep interacting with each other — contributing to the entropy of the system — and they keep trying to move towards their neighbors — contributing to the energy. If the parameters are such that entropy and energy balance perfectly then you have a criticality and features like chaos and Turing universality. However, this perfect entropy-energy balance is a knife-edge phenomena, small-disturbances tip you one way or another and the system becomes non-universal and potentially predictable. The set of parameter settings for which influence systems are unpredictable has measure zero, and a very complicated self-similar structure.
Braverman’s example had similar behavior. He considered if Julia sets — the boundary of points 



In other words, if — instead of doing worst-case analysis — we look at the smoothed analysis of influence systems and Julia sets then they are predictable. It is a matter of allowing small random perturbations around the worst-case inputs: combining the best of worst-case and average-case analysis. Does this mean we can bring back statistical mechanics? The biggest intersection between statistical mechanics and traditional theoretical computer science is in looking at phase-transitions in the 

![]() Note: this is the second blogpost of a series (first here) on the recent workshop on Natural Algorithms and the Sciences at Princeton’s Center for Computational Intractability.
Note: this is the second blogpost of a series (first here) on the recent workshop on Natural Algorithms and the Sciences at Princeton’s Center for Computational Intractability.
Chazelle, B. (2012). Natural algorithms and influence systems Communications of the ACM, 55 (12) DOI: 10.1145/2380656.2380679


Pingback: Distributed computation in foraging desert ants | Theory, Evolution, and Games Group
Pingback: Mathematical models of running cockroaches and scale-invariance in cells | Theory, Evolution, and Games Group
Pingback: Microscopic computing in cells and with self-assembling DNA tiles | Theory, Evolution, and Games Group
Pingback: Machine learning and prediction without understanding | Theory, Evolution, and Games Group
Pingback: Toward an algorithmic theory of biology | Theory, Evolution, and Games Group
Pingback: Stats 101: an update on readership | Theory, Evolution, and Games Group
Pingback: Cataloging a year of blogging: the algorithmic world | Theory, Evolution, and Games Group
Pingback: Limits of prediction: stochasticity, chaos, and computation | Theory, Evolution, and Games Group
Pingback: Reading Tracks 150802-150808 | Randomized.ME
Pingback: Hiding behind chaos and error in the double pendulum | Theory, Evolution, and Games Group
Pingback: Hiding behind chaos and error in the double pendulum | Theory, Evolution, and Games Group – Artem Kaznatcheev | Systems Community of Inquiry
Pingback: Daily Bookmarks to GAVNet 06/18/2019 | Greener Acres Value Network News