Will the droids take academic jobs?
April 20, 2013 7 Comments
As a researcher, one of the biggest challenges I face is keeping up with the scientific literature. This is further exasperated by working in several disciplines, and without a more senior advisor or formal training in most of them. The Evolutionary Game Theory Reading Group, and later this blog, started as an attempt to help me discover and keep up with the reading. Every researcher has a different approach: some use the traditional process of reading the table of contents and abstracts of selective journals, others rely on colleagues, students, and social media to keep them up to date. Fundamentally, these methods are surprisingly similar and it is upto the individual to find what is best for them. I rely on blogs, G+, Google Scholar author alerts, extensive forward-citation searches, surveys, and most recently: Google Scholar updates.

The updates are a computer filtering system that uses my publications to gage my interests and then suggests new papers as they enter Google’s database. Due to my limited publication history, the AI doesn’t have much to go on, and is rather hit or miss. Some papers, like the Requejo & Camacho reference in the screeshot above, have led me to find useful papers on ecological games and hurry my own work on environmental austerity. Other papers, like Burgmuller’s, are completely irrelevant. However, this recommendation system will improve with time, I will publish more papers to inform it and the algorithms it uses will advance.
Part of that advancement comes from scientists optimizing their own lit-review process. Three days ago, Davis, Wiegers et al. (2013) published such an advancement in PLoS One. The authors are part of the team behind the Comparative Toxicogenomics Database that (emphasis mine):
promotes understanding about the effects of environmental chemicals on human health by integrating data from curated scientific literature to describe chemical interactions with genes and proteins, and associations between diseases and chemicals, and diseases and genes/proteins.
This curation requires their experts to go through thousands of articles in order update the database. Unfortunately, not every article is relevant and there are simply too many articles to curate everything. As such, the team needed a way to automatically sort which articles are most likely to be useful and thus curated. They developed a system that uses their database plus some hand-made rules to text-mine articles and assign them a document relevance score (DRS). The authors looked at a corpus of 14,904 articles, with 1,020 of them having been considered before and thus serving as a calibration set. To test their algorithms effectiveness, 3583 articles were sampled at random from the remaining 13884 and sent to biocurators for processing. The DRS correlated well with probability of curation, with 85% curation rate for articles with high DRS and only 15% for low DRS articles. This outperformed the PubMed ranking of articles which resulted in a ~60% curation rate regardless of the PubMed ranking.
With the swell of scientific publishing, I think machines are well on their way to replacing selective journals, graduate students, and social media for finding relevant literature. Throw in that computers already make decent journalists; and you can go to SCIgen to make your own AI authored paper that is ‘good’ enough to be accepted at an IEEE conference; and your laptop can write mathematical proofs good enough to fool humans. Now you have the ingredients to remind academics that they are at risk, just like everybody else, of losing their jobs to computers. Still it is tempting to take comfort from technological optimists like Andrew McAfee and believe that the droids will only reduce mundane and arduous tasks. It is nicer to believe that there will always be a place for human creativity and innovation:
For now, the AI systems are primarily improving my workflow and making researcher easier and more fun to do. But the future is difficult to predict, and I am naturally a pessimist. I like to say that I look at the world through algorithmic lenses. By that, I mean that I apply ideas from theoretical computer science to better understand natural or social phenomena. Maybe I should adopt a more literal meaning; at this rate “looking at the world through algorithmic lenses” might simply mean that the one doing the looking will be a computer, not me.
![]() Davis, A., Wiegers, T., Johnson, R., Lay, J., Lennon-Hopkins, K., Saraceni-Richards, C., Sciaky, D., Murphy, C., & Mattingly, C. (2013). Text Mining Effectively Scores and Ranks the Literature for Improving Chemical-Gene-Disease Curation at the Comparative Toxicogenomics Database PLoS ONE, 8 (4) DOI: 10.1371/journal.pone.0058201
Davis, A., Wiegers, T., Johnson, R., Lay, J., Lennon-Hopkins, K., Saraceni-Richards, C., Sciaky, D., Murphy, C., & Mattingly, C. (2013). Text Mining Effectively Scores and Ranks the Literature for Improving Chemical-Gene-Disease Curation at the Comparative Toxicogenomics Database PLoS ONE, 8 (4) DOI: 10.1371/journal.pone.0058201

 with categorization, we can study how much ethnocentric (and traitorous) agents are willing to pay for their greater cognitive abilities. This cost directly changes the default probability to reproduce (
with categorization, we can study how much ethnocentric (and traitorous) agents are willing to pay for their greater cognitive abilities. This cost directly changes the default probability to reproduce ( ), with humanitarians and selfish agents having
), with humanitarians and selfish agents having  and ethnocentrics and traitorous agents having
and ethnocentrics and traitorous agents having  . During each cycle, the
. During each cycle, the  and providing a benefit
and providing a benefit  (that varies depending on the simulation parameters) to the partner. For more detailed presentation of the simulation and default parameter, or just to follow along on your computer,
(that varies depending on the simulation parameters) to the partner. For more detailed presentation of the simulation and default parameter, or just to follow along on your computer, 
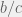 ratio and increasing
ratio and increasing 
 . From this limited data, I concluded that since the phase transition happens for
. From this limited data, I concluded that since the phase transition happens for 
 fixed at 0.01. Unsurprisingly, the transitions for proportion of ethnocentrics and humanitarians are indistinguishable, but without a proper analysis it is not clear if the transition from high to low cooperation also always coincides. For
fixed at 0.01. Unsurprisingly, the transitions for proportion of ethnocentrics and humanitarians are indistinguishable, but without a proper analysis it is not clear if the transition from high to low cooperation also always coincides. For  , agents are willing to invest more than
, agents are willing to invest more than 


Interdisciplinitis: Do entropic forces cause adaptive behavior?
April 21, 2013 by Artem Kaznatcheev 27 Comments
Reinventing the square wheel. Art by Mark Fiore of San Francisco Chronicle.
Ten years later, Elias (1958) drained the pus with surgically precise rhetoric:
I highly recommend reading the whole editorial, it is only one page long and a delight of scientific sarcasm. Unfortunately — as any medical professional will tell you — draining the abscess is treating the symptoms, and without a regime of antibiotics, it is difficult to resolve the underlying cause of interdisciplinitis. Occasionally the symptoms flare up, with the most recent being two days ago in the prestigious Physics Review Letters.
Wissner-Gross & Freer (2013) try to push the relationship between intelligence and entropy maximization by suggesting that the human cognitive niche is explained by causal entropic forces. Entropic force is an apparent macroscopic force that depends on how you define the correspondence between microscopic and macroscopic states. Suppose that you have an ergodic system, in other words: every microscopic state is equally likely (or you have a well-behaved distribution over them) and the system transitions between microscopic states at random such that its long term behavior mimics the state distribution (i.e. the ensemble average and time-average distributions are the same). If you define a macroscopic variable, such that some value of the variable corresponds to more microscopic states than other values then when you talk about the system at the macroscopic level, it will seem like a force is pushing the system towards the macroscopic states with larger microscopic support. This force is called entropic because it is proportional to the entropy gradient.
Instead of defining their microstates as configurations of their system, the authors focus on possible paths the system can follow for time into the future. The macroscopic states are then the initial configurations of those paths. They calculate the force corresponding to this micro-macro split and use it as a real force acting on the macrosystem. The result is a dynamics that tends towards configurations where the system has the most freedom for future paths; the physics way of saying that “intelligence is keeping your options open”.
into the future. The macroscopic states are then the initial configurations of those paths. They calculate the force corresponding to this micro-macro split and use it as a real force acting on the macrosystem. The result is a dynamics that tends towards configurations where the system has the most freedom for future paths; the physics way of saying that “intelligence is keeping your options open”.
In most cases to directly invoke the entropic force as a real force would be unreasonably, but the authors use a cognitive justification. Suppose that the agent uses a Monte Carlo simulation of paths out to a time horizon %latex \tau$ and then moves in accordance to the expected results of its’ simulation then the agents motion would be guided by the entropic force. The authors study the behavior of such an agent in four models: particle in a box, inverted pendulum, a tool use puzzle, and a “social cooperation” puzzle. Unfortunately, these tasks are enough to both falsify the authors’ theory and show that they do not understand the sort of questions behavioral scientists are asking.
If you are locked in a small empty (maybe padded, after reading this blog too much) room for an extended amount of time, where would you chose to sit? I would suspect most people would sit in the corner or near one of the walls, where they can rest. That is where I would sit. However, if adaptive behavior is meant to follow Wissner-Gross & Freer (2013) then, as the particle in their first model, you would be expected to remain in the middle of the room. More generally, you could modify any of the authors’ tasks by having the experimenter remove two random objects from the agents’ environment whenever they complete the task of securing a goal object. If these objects are manipulable by the agents, then the authors would predict that the agents would not complete their task, regardless of what the objects are since there are more future paths with the option to manipulate two objects instead of one. Of course, in a real setting, it would depend on what these objects are (food versus neutral) on if the agents would prefer them. None of this is built into the theory, so it is hard to take this as the claimed general theory of adaptive behavior. Of course, it could be that the authors leave “the filling in of the outline to the psychologists”.
Do their experiments address any questions psychologists are actually interested in? This is most clearly interested with their social cooperation task, which is meant to be an idealization of the following task we can see bonobos accomplishing (first minute of the video):
Yay, bonobos! Is the salient feature of this task that the apes figure out how to get the reward? No, it is actually that bonobos will cooperate in getting the reward regardless of it is in the central bin (to be shared between them) or into side bins (for each to grab their own). However, chimpanzees would work together only if the food is in separate bins and not if it is available in the central bin to be split. In the Wissner-Gross & Freer (2013) approach, both conditions would result in the same behavior. The authors are throwing away the relevant details of the model, and keeping the ones that psychologists don’t care about.
The paper seems to be an obtuse way of saying that “agents prefer to maximize their future possibilities”. This is definitely true in some cases, but false in others. However, it is not news to psychologists. Further, the authors abstraction misses the features psychologists care about while stressed irrelevant ones. It is a prime example of interdisciplinitis, and raises the main question: how can we avoid making the same mistake?
Since I am a computer scientists (and to some extent, physicist) working on interdisciplinary questions, this is particularly important for me. How can I be a good connector of disciplines? The first step seems to publish in journal relevant to the domain of the questions being asked, instead of the domain from which the tools being used originate. Although mathematical tools tends to be more developed in physics than biology or psychology, the ones used in Wissner-Gross & Freer (2013) are not beyond what you would see in the Journal of Mathematical Psychology. Mathematical psychologists tend to be well versed in the basics of information theory, since it tends to be important for understanding Bayesian inference and machine learning. As such, entropic forces can be easily presented to them in much the same way as I presented in this post.
By publishing in a journal specific to the field you are trying to make an impact on, you get feedback on if you are addressing the right questions for your target field instead of simply if others’ in your field (i.e. other physicists) think you are addressing the right questions. If your results get accepted then you also have more impact since they appear in a journal that your target audience reads, instead of one your field focuses on. Lastly, it is a show of respect for the existing work done in your target field. Since the goal is to set up a fruitful collaboration between disciplines, it is important to avoid E.O. Wilson’s mistake of treating researchers in other fields as expendable or irrelevant.
References
Elias, P. (1958). Two famous papers. IRE Transactions on Information Theory, 4(3): 99.
Shannon, Claude E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal. 27(3): 379–423.
Wissner-Gross, A.D., & Freer, C.E. (2013). Causal Entropic Forces Phys. Rev. Lett., 110 (16) : 10.1103/PhysRevLett.110.168702
Filed under Commentary, Models, Reviews Tagged with current events, information theory, intelligence, video