Semi-smooth fitness landscapes and the simplex algorithm
September 12, 2013 13 Comments
 As you might have guessed from my strange and complicated name, I’m Russian. One of the weird features of this is that even though I have never had to experience war, I still feel a strong cultural war-weariness. This stems from an ancestoral memory of the Second World War, a conflict that had an extremely disruptive affect on Russian society. None of my great-grandfathers survived the war; one of them was a train engineer that died trying to drive a train of provisions over the Road of Life to resuply Leningrad during its 29 month seige. Since the Germans blocked all the land routes, part of road ran over the ice on Lake Ladoga — trucks had to be optimally spaced to not crack the ice that separated them from a watery grave while maximizing the amount of supplies transported into the city. Leonid Kantorovich — the Russian mathematician and economist that developed linear programming as the war was starting in western Europe — ensured safety by calculating the optimal distance between cars depending on the ice thickness and air temperature. In the first winter of the road, Kantorovich would personally walk between trucks on the ice to ensure his guidelines were followed and to reassure the men of the reliability of mathematical programming. Like his British counterpart, Kantorovich was aplying the algorithmic lens to help the Allied war effort and the safety of his people. Although I can never reciprocate the heroism of these great men, stories like this convince me that the algorithmic lens can provide a powerful perspective in economics, engineering, or science. This is one of the many inspirations behind my most recent project (Kaznatcheev, 2013) applying the tools of theoretical computer science and mathematical optimization — such as linear programming — to better understand the rate of evolutionary dynamics.
As you might have guessed from my strange and complicated name, I’m Russian. One of the weird features of this is that even though I have never had to experience war, I still feel a strong cultural war-weariness. This stems from an ancestoral memory of the Second World War, a conflict that had an extremely disruptive affect on Russian society. None of my great-grandfathers survived the war; one of them was a train engineer that died trying to drive a train of provisions over the Road of Life to resuply Leningrad during its 29 month seige. Since the Germans blocked all the land routes, part of road ran over the ice on Lake Ladoga — trucks had to be optimally spaced to not crack the ice that separated them from a watery grave while maximizing the amount of supplies transported into the city. Leonid Kantorovich — the Russian mathematician and economist that developed linear programming as the war was starting in western Europe — ensured safety by calculating the optimal distance between cars depending on the ice thickness and air temperature. In the first winter of the road, Kantorovich would personally walk between trucks on the ice to ensure his guidelines were followed and to reassure the men of the reliability of mathematical programming. Like his British counterpart, Kantorovich was aplying the algorithmic lens to help the Allied war effort and the safety of his people. Although I can never reciprocate the heroism of these great men, stories like this convince me that the algorithmic lens can provide a powerful perspective in economics, engineering, or science. This is one of the many inspirations behind my most recent project (Kaznatcheev, 2013) applying the tools of theoretical computer science and mathematical optimization — such as linear programming — to better understand the rate of evolutionary dynamics.

Epistasis in fitness graphs of two loci. Arrows point from lower fitness to higher fitness, and AB always has higher fitness than ab. From left to right no epistasis, sign epistasis, reverse sign epistasis.
Computer science relies heavily on discrete math and so it is best suited for studying structural rather than statistical features of evolution. As I discussed previously, the central structure of interest for biologists studying fitness landscapes is epistasis of which there are three kinds: magnitude, sign, and reciprocal sign. The latter two can have a qualitative effect on dynamics, while the former can only have a less pronounced quantitative effect.

Shortest paths from abc to ABc are blocked by the reciprocal sign epistasis of the red edges. However, an alternative adaptive path exists along the green edges that first introduces the C allele to reach ABC, but then removes it to return to ABc.
If there is no sign epistasis in the fitness landscape then every shortest path (looking at 1-mutant neighbors but ignoring fitness) is also an adaptive path (i.e. monotonically increasing in fitness). On such a landscape, it is trivial to see that the global fitness peak is found in fewer than 
- No reciprocal sign epistasis,
- Every genotype has at least one shortest path (ignoring fitness) that is also an adaptive path (i.e. monotonically increasing in fitness) to the unique global fitness peak, and
- Every subcube of the fitness landscape has a unique fitness peak.
The last condition is the same as the definition of acyclic unique sink orientations (AUSOs) of graphs from the analysis of simplex algorithms — a class of algorithms developed by George Dantzig after the war to solve Kantorovich’s linear programs. This allows me to use the decades of rigorous results on linear programming and the simplex algorithm to analyze semi-smooth fitness landscapes. In particular, it lets me restate Matousek & Szabo’s (2006) theorem in biological terms:
Theorem 12 (Kaznatcheev, 2013):
There are positive constantssuch that for all sufficiently large
such that strong selection weak mutation (SSWM) dynamics starting from a random wild type, with probability at least
follows an adaptive path of at least
adaptive steps to the fitness peak.
Where SSWM dynamics is interpreted as selecting a mutant uniformly at random from the set of fitter 1-mutation neighbours. In other words, even though a short path exists, evolution spends exponentially long wandering around trying to find it. At first hand this might seem like an artifact of the random decisions made by SSWM, a biologist expressed this intuition very cleanly in a recent email:
If the population is large enough, it will take better steps with higher probability (see Orr’s and Gillespie’s papers). If the population is very large, it will behave almost as a greedy walker (although not quite). My intuition is that if the population takes better steps with higher probability, it will reach the peak much sooner than your theorem 12 suggests.
The power of computer science is to show that this intuition is not true. In fact, if we take the limit of extremely large populations and say that the population always selects the fittest adjacent neighbour, then it is even easier to build semi-smooth landscapes where evolution will require an exponential number of steps. Dantzig’s original version of the simplex algorithm, actually followed this infinite population strategy by always picking the best pivot (fittest mutant), and the first time a hardness result was shown was for this pivot rule!
In 1972, Klee and Minty (also: Jeroslow 1973) constructed what is now known as the Klee-Minty cube as an example of a hypercube on which Dantzig’s original simplex algorithm would take an exponential number of steps. In fact, if you started at the lowest-fitness vertex and always moved to the fittest neighbour then you would actually visit all 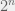

Of course, we could pick some other rule for picking mutants that hasn’t been studied before by computer scientists and assert that “this rule doesn’t take exponential time”. In particular consider the following rule, if the fitness of the current vertex is 


Given a selection rule that given a wild type
and adjacent fitter mutant
for some
. There exists a semi-smooth landscape where this selection rule results in an expected number of adaptive steps that is super-polynomial.
This conjecture is independent of biology, is true for 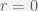


This is the sixth of a series of posts on computational considerations of empirical and theoretical fitness landscapes. In the previous post I gave a historic overview of fitness landscapes as mental and mathematical metaphors, highlighted our empirical knowledge of them, explained the Orr-Gillespie theory for minimizing statistical assumptions, introduced the NK and block models, and presented an executive summary of the computational complexity of evolutionary equilibria.
References
Amenta, N, & Ziegler, G.M. (1996). Deformed products and maximal shadows of polytopes. Advances in discrete and computational geometry. 10-19.
Crona, K., Greene, D., & Barlow, M. (2013). The peaks and geometry of fitness landscapes. Journal of Theoretical Biology.
Goldfarb, D. (1994). On the complexity of the simplex algorithm. In Advances in optimization and numerical analysis. Dordrecht, Kluwer. 25-38.
Gillespie, J.H. (1983). A simple stochastic gene substitution model. Theor. Pop. Biol. 23: 202-215.
Jeroslow, R.G. (1973). The simplex algorithm with the pivot rule of maximizing criterion improvement. Discrete Mathematics 4(4): 367-377.
Kaznatcheev, Artem (2013). Complexity of evolutionary equilibria in static fitness landscapes. arXiv preprint arXiv: 1308.5094v1.
Klee, V., & Minty, G.J. (1972). How good is the simplex algorithm?. In Shisha, Oved. Inequalities III (Proceedings of the Third Symposium on Inequalities). New York-London: Academic Press. 159–175.
Matousek, J., & Szabo, T. (2006). RANDOM EDGE can be exponential on abstract cubes. Advances in Mathematics, 204, 262-277 DOI: 10.1016/j.aim.2005.05.021
Orr H.A. (2005). The genetic theory of adaptation: a brief history. Nature Reviews Genetics, 6 (2), 119-27
Poelwijk, F.J., Kiviet, D.J., Weinreich, D.M., & Tans, S.J. (2007). Empirical fitness landscapes reveal accessible evolutionary paths. Nature 445: 383-386.
Poelwijk, F.J., Sorin, T.-N., Kiviet, D.J., Tans, S.J. (2011). Reciprocal sign epistasis is a necessary condition for multi-peaked fitness landscapes. Journal of Theoretical Biology 272: 141-144.


Pingback: Semi-smooth fitness landscapes and the simplex ...
Pingback: Semi-smooth fitness landscapes and the simplex algorithm | Theory … | Survival of Fittest
Pingback: Cataloging a year of blogging: the algorithmic world | Theory, Evolution, and Games Group
Pingback: Misleading models: “How learning can guide evolution” | Theory, Evolution, and Games Group
Pingback: Evolutionary non-commutativity suggests novel treatment strategies | Theory, Evolution, and Games Group
Pingback: Five motivations for theoretical computer science | Theory, Evolution, and Games Group
Pingback: Pairing tools and problems: a lesson from the methods of mathematics and the Entscheidungsproblem | Theory, Evolution, and Games Group
Pingback: Fusion and sex in protocells & the start of evolution | Theory, Evolution, and Games Group
Pingback: Abstract is not the opposite of empirical: case of the game assay | Theory, Evolution, and Games Group
Pingback: Local maxima and the fallacy of jumping to fixed-points | Theory, Evolution, and Games Group
Pingback: Game landscapes: from fitness scalars to fitness functions | Theory, Evolution, and Games Group
Pingback: Introduction to Algorithmic Biology: Evolution as Algorithm | Theory, Evolution, and Games Group
Pingback: The gene-interaction networks of easy fitness landscapes | Theory, Evolution, and Games Group