Limits on efficient minimization and the helpfulness of teachers.
October 1, 2013 1 Comment
Two weeks ago, I lectured on how we can minimize and learn deterministic finite state automata. Although it might not be obvious, these lectures are actually pretty closely related since minimization and learning often go hand-in-hand. During both lectures I hinted that the results won’t hold for non-deterministic finite state automata (NFA), and challenged the students to identify where the proofs break down. Of course, these is no way to patch the proofs I presented to carry over to the NFA case, in fact we expect that no efficient algorithms exist for minimizing or learning NFAs.
NFAs are hard to minimize
It is known that given an NFA (Meyer & Stockmeyer, 1972) or a DFA (Jiang & Ravikumar, 1993), finding a minimal NFA (or saying if one exists below a certain size, to make a decision problem) is PSPACE-hard. In fact, even if we consider NFAs that are simply the concatination of two DFAs, it is PSPACE-complete to answer if they are equivalent to a third DFA. More formally, given three DFAs 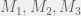
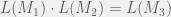




In theory, there is no difference between theory and practice. But, in practice, there is. Using SAT solvers and clever encodings can often produce NFAs that are close to minimal (Gekdenhuys, 2010). Alternatively, you can combine the classic Kameda-Weiner (1970) algorithm with some local search heuristics (Tsyganov, 2012) and get decent results in practice. Since I am purely a theorist, I would be interested to know if the local search version of NFA-minimization is PLS-hard.
NFAs are hard to learn
Under some philosophical assumptions (or by fiat), we can suppose that this world is described by a regular language 
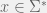


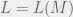

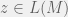

The story of learning NFAs in the MAT-model is similar to minimization. As we switch to more compact representations of regular languages, a polynomial in the size of this representation leaves with less time for learning. In fact, under cryptographic assumptions, Angluin & Kharitov (1995) showed that it is not possible to learn NFAs in time polynomial in the size of a minimal NFA representing the environment. However, there is an algorithm that learns NFAs in time polynomial in the size of the (often exponentially bigger) minimum DFA representing the environment (Yokomori, 1994). Yokomori’s learning algorithm is fundamentally different from Angluin’s (1987) and uses NFAs at every stage. However, it makes no guarantees to learn return a minimal NFA, just one consistent with the environment, and since a DFA is just another non-minimal NFA, it is not clear what advantage Yokomori’s result offers. That being said, it allows us to define a subclass called NFA<subpoly that consists of all machines where a minimal NFA is only polynomially smaller than the minimum DFA; this class would be efficiently learnable.
Residual finite state automata and the boundaries of learnability
Residual finite state automata (RFSAs, defined in Denis et al. (2002)) are another DFA-like subclass of NFAs with more algebraic structure than NFApoly. Consider a language 







In particular, like for DFAs the minimum RFSA is unique but has the same number of states as there are prime residuals of the language (Denis et al., 2002). A residual is called prime if it is not equal to the union of residual languages it strictly contains. The number of prime residuals can be exponentially smaller than the number of residuals (Denis et al., 2002). However, there are also regular languages where the smallest NFA has exponentially fewer states than the smallest RFSA. Thus, the minimum RFSA is always larger than (or equal to) the size of the minimal NFAs and smaller than (or equal to) the size of the minimum DFA, but sometimes can be exponentially larger than the NFAs, and sometimes exponentially smaller than the minimum DFA. In other words, this RFSA contains some NFAs that are not in NFApoly; Dennis et al. (2004) actually showed that all the NFAs produced by Yokomori’s algorithm are actually RFSA and usually not canonical. As far as I can tell (from looking through Berstel et al. (2010)), it is not known if RFSAs can be minimized efficiently, but Bollig et al. (2009) showed that RFSAs are efficiently learnable in Angluin’s minimally adequate teacher model. This is the most compact representation of regular languages that is currently known to be efficiently learnable. Note that efficient learnability of canonical RFSAs does not imply minimization is easy. As far as I can tell, the Bollig et al. (2009) algorithm does not imply a minimization algorithm, since the size of counter-examples is not bounded and it is not clear how to efficiently test RFSAs for equality to simulate the teacher. For example, testing two NFAs for equality is PSPACE-complete, although in practice Mayr & Clemente (2013) report that it can be done reasonably quickly.
This shows that Angluin’s learning algorithm can be improved, but not too drastically. One might also try to see if both membership and counter-example queries are necessary. As I’ve mentioned previously, Kearns & Valiant (1994) showed that assuming that we can’t crack RSA, counter-example queries are necessary. In a complementary result, Angluin (1990) showed that even without any complexity theoretic assumptions (using only information theoretic and combinatorial considerations), counter-example queries alone also don’t suffice for learning DFAs or NFAs on their own. In other words, MAT-learning of regular languages is surprisingly well characterized.
References
Angluin, D. (1987). Learning regular sets from queries and counterexamples. Information and Computation, 75: 87-106
Angluin, D. (1990). Negative results for equivalence queries. Machine Learning, 5(2): 121-150.
Angluin, D., & Kharitonov, M. (1995). When Won’t Membership Queries Help? Journal of Computer and System Sciences, 50 (2), 336-355 DOI: 10.1006/jcss.1995.1026
Berstel, J., Boasson, L., Carton, O., & Fagnot, I. (2010). Minimization of automata. arXiv preprint. arXiv:1010.5318.
Björklund, H., & Martens, W. (2008). The tractability frontier for NFA minimization. In Automata, Languages and Programming (pp. 27-38). Springer Berlin Heidelberg.
Bollig, B., Habermehl, P., Kern, C., & Leucker, M. (2009). Angluin-Style Learning of NFA. In IJCAI, 9: 1004-1009.
Denis, F., Lemay, A., & Terlutte, A. (2002). Residual finite state automata. Fundemnta Informaticae, 51(4): 339-368.
Denis, F., Lemay, A., & Terlutte, A. (2004). Learning regular languages using RFSAs. Theoretical Computer Science, 313(2): 267-294.
Geldenhuys, J., Van Der Merwe, B., and Van Zijl, L. (2010). Reducing nondeterministic finite automata with SAT solvers. In Finite-State Methods and Natural Language Processing. Springer Berlin Heidelberg, 81-92.
Jiang, T., & Ravikumar, B. (1993). Minimal NFA problems are hard. SIAM Journal on Computing, 22(6): 1117-1141. (first appeared in Automata, Languages and Programming (1991, pp. 629-640). Springer Berlin Heidelberg).
Kameda, T., & Weiner, P. (1970). On the state minimization of nondeterministic finite automata. Computers, IEEE Transactions on, 100(7), 617-627.
Kearns, M., & Valiant, L. (1994). Cryptographic limitations on learning Boolean formulae and finite automata. Journal of the ACM, 41(1), 67-95.
Malcher, A. (2004). Minimizing finite automata is computationally hard. Theoretical Computer Science, 327(3): 375-390.
Mayr, R., & Clemente, L. (2013). Advanced automata minimization. In Proceedings of the 40th annual ACM SIGPLAN-SIGACT symposium on Principles of programming languages (pp. 63-74). ACM.
Meyer, A. R., & Stockmeyer, L. J. (1972). The equivalence problem for regular expressions with squaring requires exponential space. In Switching and Automata Theory. IEEE.
Tsyganov, A.V. (2012). Local Search Heuristics for NFA State Minimization Problem. International Journal of Communications, Network and System Sciences, 5.
Yokomori, T. (1994). Learning non-deterministic finite automata from queries and counterexamples. In Machine intelligence 13 (pp. 169-189).


Pingback: Cataloging a year of blogging: the algorithmic world | Theory, Evolution, and Games Group