Memes, compound strategies, and factoring the replicator equation
December 3, 2014 16 Comments
When you work with evolutionary game theory for a while, you end up accumulating an arsenal of cute tools and tricks. A lot of them are obvious once you’ve seen them, but you usually wouldn’t bother looking for them if you hadn’t know they existed. In particular, you become very good friends with the replicator equation. A trick that I find useful at times — and that has come up recently in my on-going project with Robert Vander Veldge, David Basanta, and Jacob Scott — is nesting replicator dynamics (or the dual notion of factoring the replicator equation). I wanted to share a relatively general version of this trick with you, and provide an interpretation of it that is of interest to people — like me — who care about the interaction of evolution in learning. In particular, we will consider a world of evolving agents where each agent is complex enough to learn through reinforcement and pass its knowledge to its offspring. We will see that in this setting, the dynamics of the basic ideas — or memes — that the agents consider can be studied in a world of selfish memes independent of the agents that host them.
Factoring the replicator equation
If all you want to do is look but not touch then the replicator equation is rather pleasant:

where 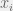


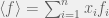

Let me be more precise.
Partition our n strategies into m sets 



![x_i = y_{i[i]}Y_{[i]}](https://s0.wp.com/latex.php?latex=x_i+%3D+y_%7Bi%5Bi%5D%7DY_%7B%5Bi%5D%7D&bg=f0f0f0&fg=555555&s=0&c=20201002)

where 

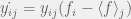
where everything is as you would expect from previous notation, except 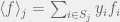

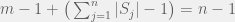
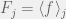

![\begin{aligned} \dot{x_i} & = \frac{d}{dt}(y_{i[i]}Y_{[i]}) = \dot{y_{i[i]}}Y_{[i]} + y_{i[i]}\dot{Y_{[i]}} \\ & = y_{i[i]}Y_{[i]}(f_i - \langle f \rangle_{[i]}) + y_{i[i]}Y_{[i]}(F_{[i]} - \langle F \rangle) \\ &= x_i(f_i - \langle f \rangle) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++%5Cdot%7Bx_i%7D+%26+%3D+%5Cfrac%7Bd%7D%7Bdt%7D%28y_%7Bi%5Bi%5D%7DY_%7B%5Bi%5D%7D%29++%3D+%5Cdot%7By_%7Bi%5Bi%5D%7D%7DY_%7B%5Bi%5D%7D+%2B+y_%7Bi%5Bi%5D%7D%5Cdot%7BY_%7B%5Bi%5D%7D%7D+%5C%5C++%26+%3D+y_%7Bi%5Bi%5D%7DY_%7B%5Bi%5D%7D%28f_i+-+%5Clangle+f+%5Crangle_%7B%5Bi%5D%7D%29+%2B+y_%7Bi%5Bi%5D%7DY_%7B%5Bi%5D%7D%28F_%7B%5Bi%5D%7D+-+%5Clangle+F+%5Crangle%29+%5C%5C++%26%3D+x_i%28f_i+-+%5Clangle+f+%5Crangle%29++%5Cend%7Baligned%7D++&bg=f0f0f0&fg=555555&s=0&c=20201002)
Of course, knowing this factoring result will not necessarily help you, since sometimes there is no simplifying structure to extract by factoring your equations. However, it is a useful result to know, and I just wanted to sketch it here for reference. I won’t provide specific applications of this result in this post, but I’ll use it in a few forthcoming posts. However, there are still some general things of note.
Eliminating the simplex
If your game only has two strategies then there is nothing to factor. Let’s look at the next simplest case: three strategies. Normally, if you have three strategies, you can start to draw a pretty simplex, either on paper, your blackboard, or with a Mathematica package like Dynamo. If you are interested — as I often am — in the qualitative dynamics then you can even turn to Bomze (1983, 1995) for a classification of the 47 possible dynamic regimes. This might be too many regimes to look through or you might hate triangles. Alternatively, you might also like the elegant logistic-like form of 2 strategy replicator dynamics. In that case, factoring is the thing for you.
Suppose your original dynamics are given by:
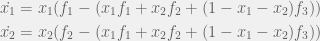
Let’s factor it into two groups 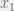




If your game then happens to have some nice structure like the function 
Re-interpreting replicator dynamics
I could leave the factorization as a cute and occasionally useful mathematical trick, but the draw for storytelling is too much for me to resist. It is much more fun to think of the compound strategies not as mere terminology or way to name sub-populations, but as agents in their own right that are playing a specific mixed strategy. The nice thing is that Bush & Mosteller’s (1951; see also Cross, 1973) model of reinforcement learning, when applied to playing games and looked at in the continuous time limit, is equivalent to replicator dynamics (Borgers & Sarin, 1997). Thus, the nested 

Thus, we can think of the 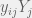

But, It is still fun to imagine such a world of selfish memes. I suspect it would look something like this:
References
Beppu, A., & Griffiths, T. L. (2009). Iterated learning and the cultural ratchet. In Proceedings of the 31st Annual Conference of the Cognitive Science Society (pp. 2089-2094). Austin, TX: Cognitive Science Society.
Bomze, I. M. (1983). Lotka-Volterra equation and replicator dynamics: a two-dimensional classification. Biological Cybernetics, 48(3): 201-211.
Bomze, I. M. (1995). Lotka-Volterra equation and replicator dynamics: new issues in classification. Biological Cybernetics, 72(5): 447-453.
Börgers, T., & Sarin, R. (1997). Learning through reinforcement and replicator dynamics Journal of Economic Theory, 77 (1), 1-14 DOI: 10.1006/jeth.1997.2319
Bush, R. R., & Mosteller, F. (1951). A mathematical model for simple learning. Psych. Rev., 58: 313-323.
Cross, J.G. (1973). A stochastic learning model of economic behavior. Quart. J. Econ., 87: 239-266.
Tennie, C., Call, J., & Tomasello, M. (2009). Ratcheting up the ratchet: on the evolution of cumulative culture. Philosophical Transactions of the Royal Society B: Biological Sciences, 364(1528): 2405-2415.


Reblogged this on CancerEvo and commented:
Artem (with help from Robert Vander Velde and yours truly) has been working on a new model where three different types of players produce and consume two different types of public goods. Here he describes a neat trick to better handle this.
Pingback: Cataloging a year of blogging: cancer and biology | Theory, Evolution, and Games Group
Pingback: Double public goods games and acid-mediated tumor invasion | Theory, Evolution, and Games Group
“if strategy 1 is some sort of defector and strategy 2 are different kinds of cooperators”
I think this is a typo, strategy 1 and 2 are cooperators and 3 is a defector (at least in the scenario proposed), correct?
I don’t propose any scenario in this post. The post is suppose to stand largely on its own, so don’t let the similarity of letter choices here to the choices I made in our work mislead you. The main point is that if the dependence on p is eliminated (which actually doesn’t quiet happen in our work anymore, given that pesky 1 – p in the denominator) then the factored equation is very easy to analyze.
Pingback: Symmetry in tag-based games & invariants under replicator dynamics | Theory, Evolution, and Games Group
Pingback: From linear to nonlinear payoffs in the double public goods game | Theory, Evolution, and Games Group
Pingback: Evolutionary dynamics of cancer in the bone | Theory, Evolution, and Games Group
Pingback: Cataloging a year of blogging | Theory, Evolution, and Games Group
Pingback: Lotka-Volterra, replicator dynamics, and stag hunting bacteria | Theory, Evolution, and Games Group
Pingback: Acidity and vascularization as linear goods in cancer | Theory, Evolution, and Games Group
Pingback: Hamiltonian systems and closed orbits in replicator dynamics of cancer | Theory, Evolution, and Games Group
Pingback: Argument is the midwife of ideas (and other metaphors) | Theory, Evolution, and Games Group
Pingback: Cataloging a year of cancer blogging: double goods, measuring games & resistance | Theory, Evolution, and Games Group
Pingback: Ontology of player & evolutionary game in reductive vs effective theory | Theory, Evolution, and Games Group
Pingback: Replicator dynamics and the simplex as a vector space | Theory, Evolution, and Games Group