Replicator dynamics and cognitive cost of agency
October 3, 2011 5 Comments
During the June 3rd Friday meeting of the LNSC, Akash Venkat asked a fun question of how simple it is to remember your strategy. I interpreted this as a question about how difficult it is to have a deterministic or low-entropy strategy. In other words, a question about the fitness of deterministic vs. randomized strategies. Last week I expressed my skepticism towards randomized strategies for ethnocentrism, this post is meant as a potential counter-balance for ideas we can use to look at randomized strategies.
After the LNSC meeting as I was on the train back to Waterloo, I did some calculations to see how to start thinking about this question. In particular, how to properly tax the cognition associated with behaving non-randomly.
The ability to perform actions (as opposed to randomly floating around in an environment) can be see as the key quality of agency. In an EGT setting, we can capture this idea by saying the strategies that are close to random have low agency, and strategies that are close to deterministic have high agency. Having high energy requires more sophisticated cognition on the part of the agent, and thus we can associate a cost 

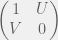
For this game we have the standard deterministic strategies C and D, and we will now add the random strategy R which with a 50% probability plays C and otherwise plays D. Thus R captures the idea of the least possible agency, and we give it a bonus 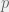


From these equations, we can see that 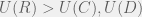


Thus, an agent is not willing to pay more than 
R is not ESS:

In other words, if we are really close to the line in game space given by 
Although at first sight the non-agent strategy being 50%-50% seems natural, it is in fact arbitrary. If we are taking the viewpoint that the non-agent players are simply allowing the environment to pick the action for them, then there is no reason to assume that the environment is unbiased between C and D. It is very reasonable to believe that action C might be more difficult than action D (or vice-versa) and the environment will have a non 50%-50% chance of selection one or the other for the player.
We could introduce a new parameter 
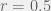
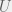
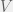

Note that this equation is not fundamentally different from the previous ones, and just provides a linear offset to the cognitive cost. This tells us that the natural measure of complexity should be linear in the agent’s degree of randomness. In other words, for a strategy space where an agent can evolve any
randomness factor 
natural choice for cognitive complexity 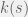

Do you think this is a viable model for the cognitive cost of agency? Or should we capture agency in some other way? What do you expect will happen when we take this game over to a structured environment? I expect that unlike the well mixed case, in certain circumstances, the agents will be willing to pay for access to randomness (instead of access to determinism).


Pingback: How would Alan Turing develop biology? « Theory, Evolution, and Games Group
Pingback: Evolutionary games in finite inviscid populations « Theory, Evolution, and Games Group
Pingback: Ohtsuki-Nowak transform for replicator dynamics on random graphs « Theory, Evolution, and Games Group
Pingback: Cooperation and the evolution of intelligence | Theory, Evolution, and Games Group
Pingback: Cooperation through useful delusions: quasi-magical thinking and subjective utility | Theory, Evolution, and Games Group