How teachers help us learn deterministic finite automata
September 24, 2013 4 Comments
Many graduate students, and even professors, have a strong aversion to teaching. This tends to produce awful, one-sided classes that students attend just to transcribe the instructor’s lecture notes. The trend is so bad that in some cases instructors take pride in their bad teaching, and at some institutions — or so I hear around the academic water-cooler — you might even get in trouble for being too good a teacher. Why are you spending so much effort preparing your courses, instead of working on research? And it does take a lot of effort to be an effective teacher, it takes skill to turn a lecture theatre into an interactive environment where information flows both ways. A good teacher has to be able to asses how the students are progressing, and be able to clarify misconceptions held by the students even when the students can’t identify those conceptions as misplaced. Last week I had an opportunity to excercise my teaching by lecturing Prakash Panangaen’s COMP330 course.
Although it might be hard to guess from this blog — with all that discussion of biology, cancer, cognitive science, economics, evolution, philosophy, and social science — that the closest label to what I study officially is probably machine learning and automata theory (I am tempted to throw ‘theoretical’ in front of that, to save myself from writing actual code). As such, on Tuesday I explained a standard automata theory topic — minimizing DFAs, but on Thursday moved onto learning DFAs — a topic seldom covered in an undergraduate automata theory courses (or even in an introductory machine learning course). It was my round-about way of justifying my existence to the students: “I can provide you with counter-examples queries!”
Imagine that we are trying to learn about the world around us, and can run experiments described by strings over 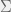

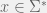





Not so if we add a teacher. Angluin (1987) defines a minimal adequate teacher (MAT) as an oracle that can answer counterexample queries. The student can give a candidate DFA 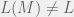

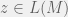


From observation tables to machines
We call a set 
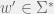
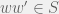
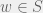
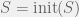
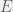

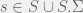
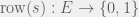

An observation table is closed if:
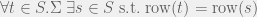
and the observation table is consistent if:

If an observation table is both closed and consistent then we can define a DFA 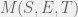




Lemma 1:
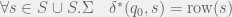
Proof: By induction on length of 
Lemma 2:

Proof: By induction on length of 
Since the machine yields the right result on every entry of 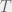
Lemma 3: Suppose that
is consistent with
is isomorphic to
We will proceed by building an isomorphism 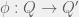

Claim 3.1:
is a bijection.
Proof: For all 
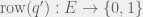
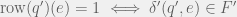
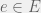

Thus, as 





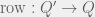
Lemma 3.2:
— the function preserves initial states.
Proof:
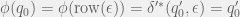
Lemma 3.3:
— the function preserves final states.
Proof: 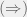
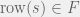

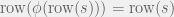
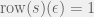
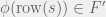

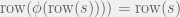

Lemma 3.4
— the function preserves transitions.
Proof: Note that 



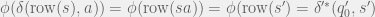
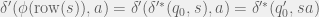
But 
Angluin-Schapire learning algorithm
Angluin (1987) provided a nice algorithm for learning DFAs using observation tables, but it is no longer the best known algorithm. In his thesis, Schapire (1991) presented an improved algorithm that I will sketch here. This algorithm will never have a non-consistent table, and will add only one element to
- Initalize S & E to
- Ask membership queries for
and each
- Construct the initial observation table (S,E,T)
- Repeat until teacher says “Correct”:
- While (S,E,T) is not closed:
- Find
such that
.
- Add
to
- Find
- Let
and ask teach if M is correct.
- If the teacher replies with a counter-example z, then let
, add
- While (S,E,T) is not closed:
- Return M and Halt

The last ingredient is find_extend, which will return a counter-example that can serve as a witness to separate two states we previously thought to be equivalent. In particular, it will return and
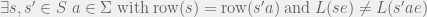
find_extend(z,M):
- Using lazy evaluation, consider the partitions
for every $latex 0 \leq |p_i| = i \leq |z| = m.
- Using lazy evaluation, let
be the state of M if you run it on
, i.e. such that
- Notice that
because z is a counter-example
- Since the two extreme values of
have different results, there must be some
such that
. Find such a
- Return
.
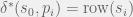
I leave it to the reader to implement the binary search and achieve a number of membership queries equal to 

References
Angluin, D. (1978). On the complexity of minimum inference of regular sets. Information and Control, 3(39):337–350.
Angluin, D. (1987). Learning regular sets from queries and counterexamples. Information and Computation,, 75, 87-106 DOI: 10.1016/0890-5401(87)90052-6
Gold, E.M. (1978). Complexity of automaton identification from given data. Information and Control, 3(37):302–420.
Kearns, M., & Valiant, L. (1994). Cryptographic limitations on learning Boolean formulae and finite automata. Journal of the ACM, 41(1), 67-95.
Schapire, R. E. (1991). The design and analysis of efficient learning algorithms. (No. MIT/LCS/TR-493) MIT, Cambridge, USA


Some work I did in the 80s —
• Theme One Program
Pingback: Limits on efficient minimization and the helpfulness of teachers. | Theory, Evolution, and Games Group
Pingback: Cataloging a year of blogging: the algorithmic world | Theory, Evolution, and Games Group
Pingback: Cross-validation in finance, psychology, and political science | Theory, Evolution, and Games Group