Critique of Chaitin’s algorithmic mutation
July 8, 2012 4 Comments
Last week, I reviewed Gregory Chaitin’s Proving Darwin. I concentrated on a broad overview of the book and metabiology, and did not touch on the mathematical details; This post will start touching. The goal is to summarize Chaitin’s ideas more rigorously and to address Chaitin’s comment:
I disagree with your characterization of algorithmic mutations as directed.
They are in fact random.
Rgds,
GJC
Specifically, I need to (a) summarize the mathematical details of algorithmic mutations, (b) clarify the distinction between random mutation and (what I called) randomized directed mutation, and (c) defend my assertion that algorithmic mutations are not purely random but directed. I need to fully explain my earlier claim:
The algorithmic mutation actually combine the act of mutating and selecting into one step, it is a
-bit program that takes the current organism A and outputs a new organism B of higher fitness (note, that it needs an oracle call for the Halting-problem to do so). The probability that A is replaced by B is then
. There is no way to decouple the selection step from the mutation step in an algorithmic mutation, although this is not clear without the technical details which I will postpone until a future post. Chaitin’s model does not have random mutations, it has randomized directed mutations.
The high level description of algorithmic mutations given in Chapter 5 is not necessarily inconsistent with random mutations, but it is not detailed enough to make a concrete judgement. We have to look at Appendix 2 (The Heart of the Proof) to really understand how Chaitin’s mutations act. As before, an organism 
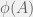

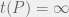
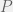
A mutation 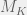

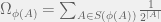


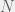





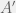
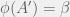
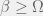
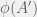
To simulate evolution (as opposed to a deterministic picking of mutations), Chaitin selects the mutations randomly (with mutation 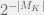
Is Chaitin’s model the simplest it can be? Chaitin spends the first four chapters defending algorithms/software as metaphors for genes; Does metabiology actually use the power of algorithms? Chaitin does not attempt to address abiogenesis in his model and the first organism is an arbitrary program. Every subsequent program arises from the original by a sequence of algorithmic mutations; but every mutation returns an program of the form 
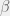
N = 1
whiledo N = N + 1 end
print N
I hid the subroutine that computes 

and the mutation operator:

and metabiology remains completely unchanged, with the exception of the original organism which we can just set as 0 for our purposes. Of course, instead of the fitness growing higher and higher it grows to be a better and better lower bound for 
Further, by looking at metabiology in the simple terms I described above we can also overcome the directed nature of ‘algorithmic’ mutations. We just modify the mutation operator to be indexed by K and either – or + with both K and – or + selected from some distribution. A natural distribution is to pick K proportional to 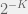

and

Then given a focal organism 

References
Chaitin, G. (2009). Evolution of Mutating Software EATCS Bulletin, 97, 157-164


Pingback: Critique of Chaitin’s algorithmic mutation | Metabiology | Scoop.it
Chaitin’s model doesn’t allow just the M_k mutations, but all the halting mutations.
Chaitin proved that if you always choose a M_k mutation, you will get the maximum “intelligent design” fitness increase, while if you choose mutations randomly, at each step you will pick a M_k mutation with probability O(1/(k(log k)^2)), yielding a slowdown in fitness increase between quadratic and cubic compared to “intelligent design”.
Sorry it took me a while to respond (your comment actually got caught in the spam filter). Chaitin definitely claims this in his main text, but if you want to look at his actual model then take a look at “Appendix 2” (pg. 111 – 114) of the book. My description is based completely on that proof.
Pingback: Micro-vs-macro evolution is a purely methodological distinction | Theory, Evolution, and Games Group