Basic model of citation network dynamics
May 13, 2012 1 Comment
This is a note based on a May 17, 2010 discussion with Julian Z. Xue outlining some of the basic ideas behind a model for citation networks and their dynamics. Inherent in our model, is the need to study dynamics of citation networks over time. How do papers accumulate citations? How do researchers decide which papers to read? What publishing strategies do they use? How much of their attention is devoted to new papers, and how much to well established ones? This already provides us a basic model of actors and the dynamic domain.
The actors: scientists
The actors in our model, are the `scientist’ entities that decide on how to allocate their time between the myriad papers they could read, and decide when they have read enough to publish a paper based on the insights they gained. Associated with each scientist 

The dynamic domain, however, is not the scientists, but the papers and citations. Although we might eventually explore the dynamics of which scientists perform better (evolutionary dynamics), or how individual scientists might optimize their own impact (local Hill-Climbing), the starting point can be a fixed distribution of scientist and what kind of network of papers such a distribution produces.
The dynamic domain: the paper-citation network
The primary dynamic domain is the papers and the citation network between them. We will represent this network as a directed acyclic graph (lets keep references of `in press’ works – and the potential cause of cycles – out of this for now) 
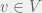
is the awesomeness of
. This might not be the most technical term, but it is suppose to capture the basic inherent quality of a paper. Sure, the impact of a paper might be influenced by how fashionable the topic is, how well known the author is, and chance occurrences. However, there is still some inherent “awesomeness” to a quality paper, usually in the form of technical merit, soundness, clarity, and novelty of ideas (of course, novelty is inherently time-dependent, and we will return to that). This parameter is private.
is the age of
and increment by
at each time step. There are two reasons we want to track age: (1) this is suppose to be a dynamic model, we need a time parameter, and (2) we want the novelty of papers to disappear with time. This parameter is public.
The parameters 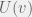



Where 

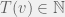
The dynamics: publications
At each time step, an agent 
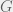


New publications
Once an agent 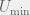


then the scientist can use 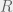
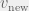
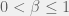
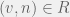


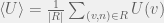
Note that in the above case we do not discount the mean awesomeness by the researchers reuse of the paper. Although the paper cannot spark the same amount of new ideas needed for the researcher who used it (to clear the min threshold), for other researchers, 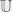


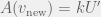
Where 
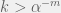


The last important factor is to chose a distribution
or included in any other paper. For simplicity I think we should assume.
- The distribution must have a variance that is easily changed between fields (since I think it might play an important part).
- The variance must be independent of the mean. Changing the mean should not alter the variance. Thus, all papers will have the same variance regardless of their generating distribution. This suggests that the distribution must be described by at least two parameters.
What are some sample distributions? Well, if we ignore point 3 for now, then the distribution that yields 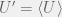
Finally, when 




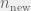



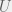
The agents’ strategy space
The last point to consider, and potentially the most important (and currently weakest) one is the strategy space from which agents can chose (or be given) their strategies. In particular, there are two primary parts of the strategy: (1) how does an agent choose which papers to read, and (2) when does the agent decide to publish a new paper. The first is inherently simpler than the second, since we just need to specify a simple utility for each vertex and just chose the one that maximizes it. In the second one it is not as clear cut — even determining the state space will take some thought.
Choosing reading material
There is a simple approach to this part of the agents strategy space. In particular, this can be solved by standard game theoretic assumptions. Provide for each agent a function 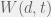




This is an obviously rational assumption, since given a fixed age, the paper with a higher in-degree is a better choice. Alternatively, given two papers with the same in-degree, the paper that is younger is a better choice (due to the discounting by age). However, what really matters, is how the two partial derivatives relate to each other. Hence, the simplest model we can construct is:
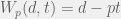
For some constant 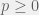

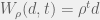
For some constant 
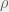

Deciding when to publish
The problem of deciding when to publish is much less clear cut than deciding what to read. We can make some rationality assumptions. For instance given sets 


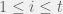
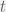





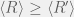
The only other rationality assumption that seems obvious to me is the one on reusable papers. Assume an agent has a subset 
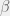
In general, I think the total strategy space for deciding when to publish is rather complicated. For this preliminary model we will have to drastically simplify it. One such simplification is to give each agent access to the mean utility of all the papers published so far — 


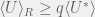
Fitness: Impact or Awesomeness?
To study this question from an evolutionary game theory point of view, we need to define a fitness function. Here, there are two approaches, both involve looking at all the papers published by an author. One way is to look at impact: the number of citations to an author. The beauty of this approach is that we can use existing metrics based on citations such as mean citations, the h-index or some of the derivatives from it. On the other hand, since we have access to awesomeness, we could also use if for fitness (mean awesomeness of papers). The best thing is, we can combine all of the above, and by finding a good awesomeness metric we could compare how well impact factor ones (such as h-index) can recreate the ones based on awesomeness. That would tell us which impact factor system is best.
List of parameters
Let us look at all the parameters mentioned for the model with the `simplest’ assumptions:
where
.
ofto avoid the self-recycling problem. In particular,
These parameters along with the initial graph specify the environment in which agents live. Along with these, we have two parameters associated with agents:
I expect
- NL —
. A repeater of new results. Simply try to jump on new wagons with minor contributions.
- NH —
. An innovator: reads the newest literature and synthesizes it into a quality product.
- OL —
. A philosopher: concentrates on making quick minor contributions to already well studied fields.
- OH —
. A theory builder: takes well established results and builds good things from them.
With that we can relabel he population strategy space as a vector on 



Is there any ways to simplify this model? Or is there essential parts missing that are needed to even be remotely useful? Do you know examples of similar models in the literature?

