Rationality for Bayesian agents
January 28, 2013
by Artem Kaznatcheev
One of the requirements of our objective versus subjective rationality model is to have learning agents that act rationally on their subjective representation of the world. The easiest parameter to consider learning is the probability of agents around you cooperating or defecting. In an one shot game without memory, your partner cannot condition their strategy on your current (or previous actions) directly. However, we don’t want to build knowledge of this into the agents, so we will allow them to learn the conditional probabilities 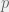 of seeing a cooperation if they cooperate, and
of seeing a cooperation if they cooperate, and  of seeing a cooperation if they defect. If the agents learning accurately reflects the world then we will have
of seeing a cooperation if they defect. If the agents learning accurately reflects the world then we will have  .
.
For now, let us consider learning , the other case will be analogous. In order to be rational, we will require the agent to use Bayesian inference. The hypotheses will be  for
for 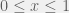 — meaning that the partner has a probability
— meaning that the partner has a probability  of cooperation. The agent’s mind is then some probability distribution
of cooperation. The agent’s mind is then some probability distribution 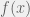 over , with the expected value of
over , with the expected value of  being . Let us look at how the moments of change with observations.
being . Let us look at how the moments of change with observations.
Suppose we have some initial distribution  , with moments
, with moments ![m_{0,k} = \mathbb{E}_{f}[x^k]](https://s0.wp.com/latex.php?latex=m_%7B0%2Ck%7D+%3D+%5Cmathbb%7BE%7D_%7Bf%7D%5Bx%5Ek%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) . If we know the moments up to step
. If we know the moments up to step 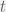 then how will they behave at the next time step? Assume the partner cooperated:
then how will they behave at the next time step? Assume the partner cooperated:
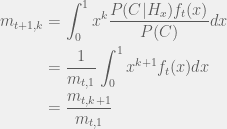
If the partner defected:
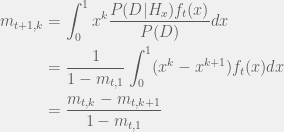
Although tracking moments is easier than updating the whole distribution and sufficient for recovering the quantity of interest ( — average probability of cooperation over ), it can be further simplified. If  is the uniform distribution, then
is the uniform distribution, then  . What are the moments doing at later times? They’re just counting, which we will prove by induction.
. What are the moments doing at later times? They’re just counting, which we will prove by induction.
Our inductive hypothesis is that after observation, with  of them being cooperation (and thus
of them being cooperation (and thus 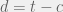 defection), we have:
defection), we have:
 .
.
Note that this hypothesis implies that
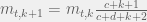 .
.
If we look at the base case of  (and thus
(and thus  ) then this simplifies to
) then this simplifies to
 .
.
Our base case is met, so let us consider a step. Suppose that our  -st observation is a cooperation, then we have:
-st observation is a cooperation, then we have:
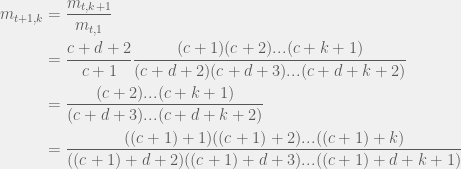 .
.
Where the last line is exactly what we expect: observing a cooperation at step  means we have seen a total of
means we have seen a total of  cooperations.
cooperations.
If we observe a defection on step , instead, then we have:
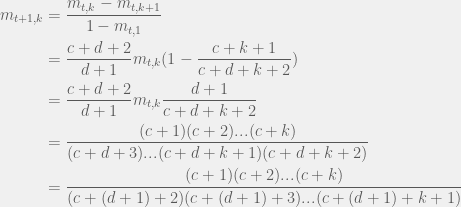
Which is also exactly what we expect: observing a defection at step means we have seen a total of  defections. This completes our proof by induction, and means that our agents need to only store the number of cooperations and defections they have experienced.
defections. This completes our proof by induction, and means that our agents need to only store the number of cooperations and defections they have experienced.
I suspect the above theorem is taught in any first statistics course, unfortunately I’ve never had a stats class so I had to recreate the theorem here. If you know the name of this result then please leave it in the comments. For those that haven’t seen this before, I think it is nice to see explicitly how rationally estimating probabilities based on past data reduces to counting that data.
Our agents are then described by two numbers giving their genotype, and four for their mind. For the genotype, there is the values of 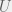 and
and 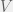 that mean that the agent thinks it is playing the following cooperate-defect game:
that mean that the agent thinks it is playing the following cooperate-defect game:
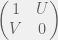
For the agents’ mind, we have  which is the number of cooperations and defections the agents saw after cooperation, and
which is the number of cooperations and defections the agents saw after cooperation, and  is the same following a defection. From these values and the theorem we just proved, the agent knows that
is the same following a defection. From these values and the theorem we just proved, the agent knows that  and
and 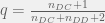 . With these values, the agent can calculate the expected subjective utility of cooperating and defecting:
. With these values, the agent can calculate the expected subjective utility of cooperating and defecting:
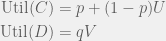
If 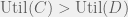 then the agent will cooperate, otherwise — defect. This has a risk of locking an agent into one action forever, say cooperate, and then never having a chance to sample results for defection and thus never update . To avoid this, we use the trembling-hand mechanism (or
then the agent will cooperate, otherwise — defect. This has a risk of locking an agent into one action forever, say cooperate, and then never having a chance to sample results for defection and thus never update . To avoid this, we use the trembling-hand mechanism (or  -greedy reinforcement learning): with small probability the agent performs the opposite action of what it intended.
-greedy reinforcement learning): with small probability the agent performs the opposite action of what it intended.
The above agent is rational with respect to its subjective state  but could be acting irrationally with respect to the objective game
but could be acting irrationally with respect to the objective game  and proportion of cooperation
and proportion of cooperation  .
.


Pingback: Quasi-magical thinking and superrationality for Bayesian agents | Theory, Evolution, and Games Group
Pingback: Evolving useful delusions to promote cooperation | Theory, Evolution, and Games Group
Pingback: Cooperation through useful delusions: quasi-magical thinking and subjective utility | Theory, Evolution, and Games Group
Pingback: Cataloging a year of blogging: from behavior to society and mind | Theory, Evolution, and Games Group
Pingback: Useful delusions, interface theory of perception, and religion. | Theory, Evolution, and Games Group
I really want to understand the details of this article so that I can further understand the subjective/ objective reality model. I hope that you can help.
1. For the first paragraph, I do not understand the setup. In the beginning what is going on? what exactly is being modeled? And why this statement, ” If the agents learning accurately reflects the world then we will have p = q.” ?
2. Is H a random variable and f the mass function? If so what is the sample space or the experiment? i.e. P(H=x) = \int_0^1 f(x)dx ??
I do not understand, ” The agent’s mind is then some probability distribution f(x) over H_x, with the expected value of f being p.”
3. Starting with the third paragraph, f_0 is the initial distribution of what? In the formula for m_{0,k} should that be f or f_0? Where do the moments come from?
thanks john
Thank you for your interest. The details of this article are not necessary for the subjective/objective rationality model since the main results hold with or without the mechanism discussed here in place (and would also hold for reasonable variations of this mechanism). However, I’ll answer your questions for completeness.
[1] The model is the following, a focal agent (call her Alice) interacts with some other agent (call him Bob). Alice and Bob decide and announce simultaneously if they will cooperate or defect. In order to make her decision, Alice wants to have some idea of the probability that Bob will decide to cooperate; she bases this on Bayesian learning from previous interactions with other agents.
Thus, she wants to estimate two probabilities: p is the probability that Bob will cooperate if Alice cooperates and q is the probability that Bob will cooperate if Alice defects. Note that since Alice and Bob make their decision simultaneously, Alice’s choice cannot actually affect Bob’s choice; so with proper reasoning and perfect knowledge, one would know that p = q. However, we allow for the possibility of agents not coming to this conclusion, so that we have a framework in which we can model things like quasi-magical thinking.
[2] That is correct. The state space of hypotheses , the state space of data is if an agent cooperated or defected. The agents is a Bayesian reasoner that has some beliefs about each hypothesis
, the state space of data is if an agent cooperated or defected. The agents is a Bayesian reasoner that has some beliefs about each hypothesis  being true, thus their ‘mind’ is simply all that information together; in other words their minds is the probability distribution f over
being true, thus their ‘mind’ is simply all that information together; in other words their minds is the probability distribution f over  . From this probability distribution over hypotheses, they need to know the expected probability that Bob will cooperate; that is simply the mean of f.
. From this probability distribution over hypotheses, they need to know the expected probability that Bob will cooperate; that is simply the mean of f.
[3] The prior distribution that the agent has before any experience. In the first calculation, it is treated generally (so it can be any distribution you want) and then after paragraph 4, I consider the special case of being the uniform distribution. The moments come from the probability distribution.
being the uniform distribution. The moments come from the probability distribution.
I hope this was helpful. You should take a look at our paper, where this is also discussed.
Thanks for your response.
[2] Let W ={ (x_i)| x_i = C or D}. Each (x_i) is a finite (infinite) sequence that represents an iterated game played between A and B OR W could be a collection of many such games played by many players. In any event H: W —> [0,1] by H(w) = longterm proportion of C’s or the probability of obtaining a C given that A or first player played a C.
Then H is a random variable and P( a <= H <= b) = int_a^b f(x)dx.
Is this the setup?
[3] Also m_{0,k} = E_{f_{0}}[x^k]?? In other words what is the relationship between f and f_0? Also could you go thru a few of the steps in your determination of m{t+1,k}. In particular, how to get the m_{t,1} in the denominator.
Thanks John
Pingback: Rationality, the Bayesian mind and its limits | Theory, Evolution, and Games Group